Ray 用于机器学习基础设施#
小技巧
如果您正在使用 Ray 构建机器学习平台,我们非常乐意听到您的声音!填写 这个简短的表格 以参与进来。
Ray 及其 AI 库为寻求简化其 ML 平台的团队提供了统一的计算运行时。Ray 的库如 Ray Train、Ray Data 和 Ray Serve 可用于组合端到端的 ML 工作流,提供数据预处理作为训练的一部分的功能和 API,并实现从训练到服务的过渡。

为什么选择 Ray 用于机器学习基础设施?#
Ray 的 AI 库通过提供无缝、统一和开放的可扩展机器学习体验,简化了机器学习框架、平台和工具的生态系统:

1. 无缝开发到生产: Ray 的 AI 库减少了从开发到生产的摩擦。通过 Ray 及其库,相同的 Python 代码可以无缝地从笔记本电脑扩展到大型集群。
2. 统一的机器学习API和运行时: Ray的API使得在流行的框架之间切换,如XGBoost、PyTorch和Hugging Face,只需最小的代码更改。从训练到服务的所有操作都在单一运行时(Ray + KubeRay)上运行。
3. 开放与可扩展: Ray 是完全开源的,可以在任何集群、云或 Kubernetes 上运行。基于可扩展的开发者 API 构建自定义组件和集成。
基于Ray构建的示例机器学习平台#
Merlin 是 Shopify 基于 Ray 构建的机器学习平台。它支持快速迭代和 分布式应用的扩展,如产品分类和推荐。
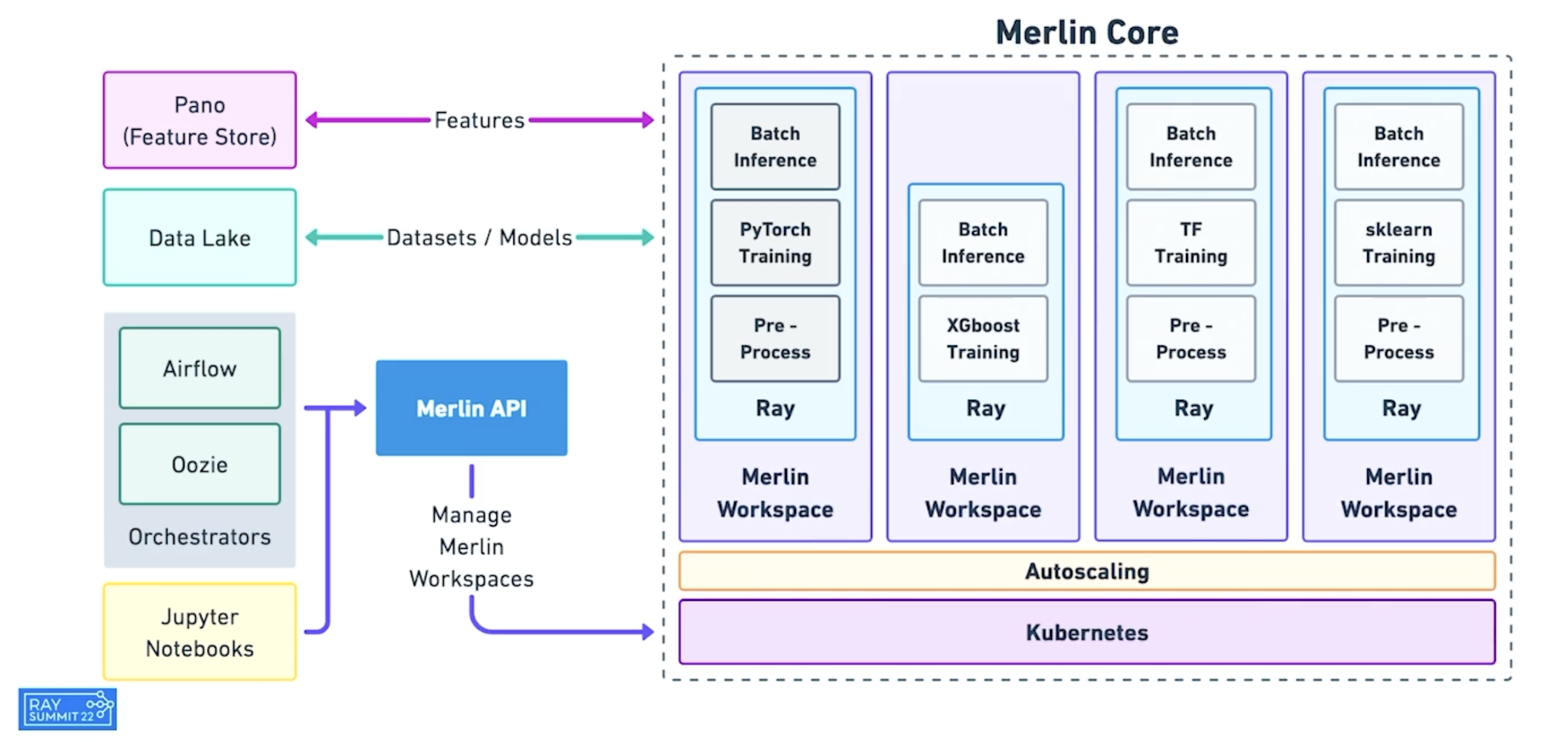
基于 Ray 构建的 Shopify 的 Merlin 架构。#
Spotify 使用 Ray 进行高级应用,包括个性化家庭播客的内容推荐,以及个性化 Spotify Radio 的曲目顺序。
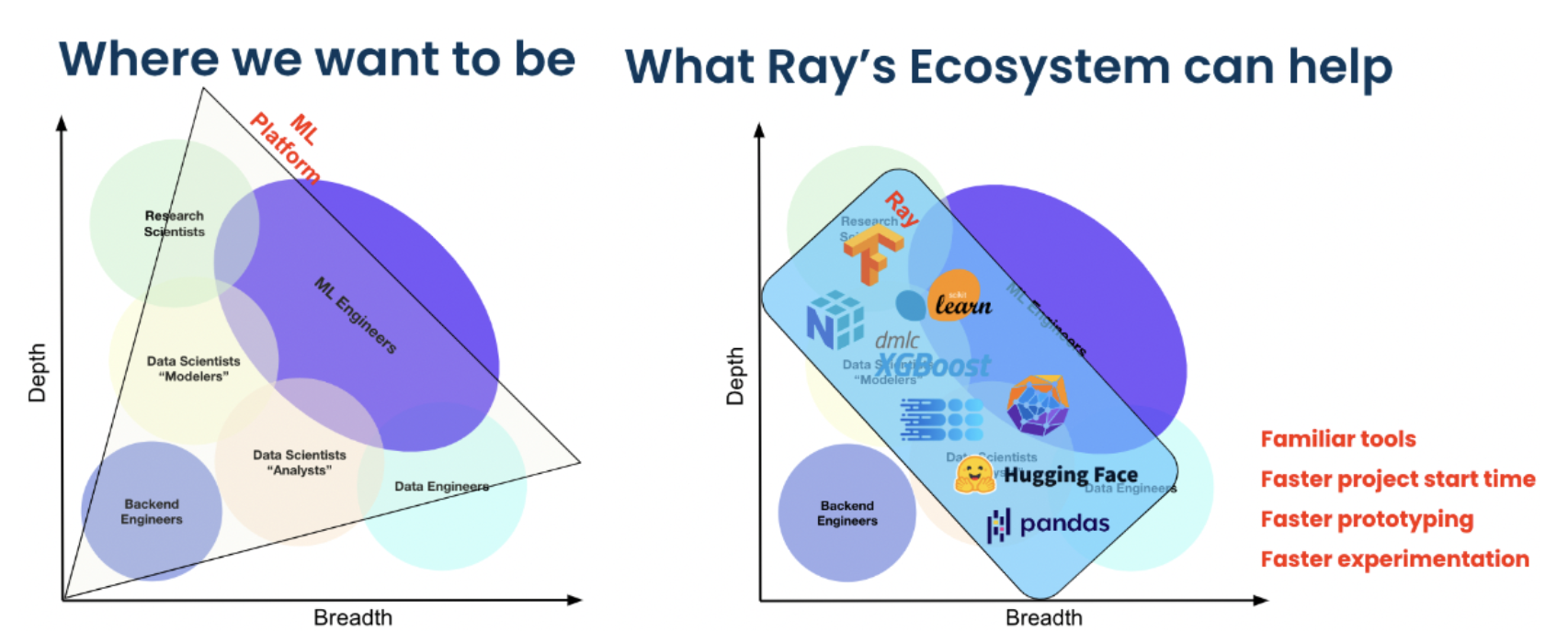
Ray 生态系统如何赋能 Spotify 的机器学习科学家和工程师。#
以下重点介绍了利用 Ray 的统一 API 构建更简单、更灵活的 ML 平台的公司。
部署 Ray 用于机器学习平台#
在这里,我们描述了如何在您的基础设施中使用或部署 Ray。有两种主要的部署模式——选择和现有平台内。
核心思想是,Ray 可以与您现有的基础设施和集成工具 互补。
设计原则#
Ray 及其库处理 AI 应用和服务中的重量级计算方面。
Ray 依赖于外部集成(例如,Tecton、MLFlow、W&B)进行存储和跟踪。
工作流编排器(例如,AirFlow)是一个可选组件,可用于调度重复作业、为作业启动新的 Ray 集群以及运行非 Ray 计算步骤。
在单个 Ray 应用中,可以使用 Ray 任务来处理任务图的轻量级编排。
Ray 库可以独立使用,可以在现有的 ML 平台中使用,或者用于构建 Ray 原生的 ML 平台。
选择你自己的库#
你可以选择使用哪些 Ray AI 库。
如果你是一名希望独立使用Ray库来实现特定AI应用或服务用例的机器学习工程师,并且不需要与现有的机器学习平台集成,那么这对你适用。
例如,Alice 想使用 RLlib 来训练她的工作项目的模型。Bob 想使用 Ray Serve 来部署他的模型管道。在这两种情况下,Alice 和 Bob 都可以独立利用这些库,无需任何协调。
此场景描述了当今Ray库的大多数用法。

在上图中:
只使用了一个库 – 这表明你可以选择性地使用,而不需要替换所有的机器学习基础设施来使用 Ray。
你可以使用 Ray 的多种部署模式之一 来启动和管理 Ray 集群和 Ray 应用程序。
Ray AI 库可以从外部存储系统(如 Amazon S3 / Google Cloud Storage)读取数据,也可以将结果存储在那里。
现有 ML 平台集成#
您可能已经有一个现有的机器学习平台,但希望使用Ray的ML库的某个子集。例如,一名ML工程师希望在其组织购买的ML平台(例如,SageMaker,Vertex)中使用Ray。
Ray 可以通过与现有的管道/工作流编排器、存储和跟踪服务集成,来补充现有的机器学习平台,而无需替换整个ML平台。
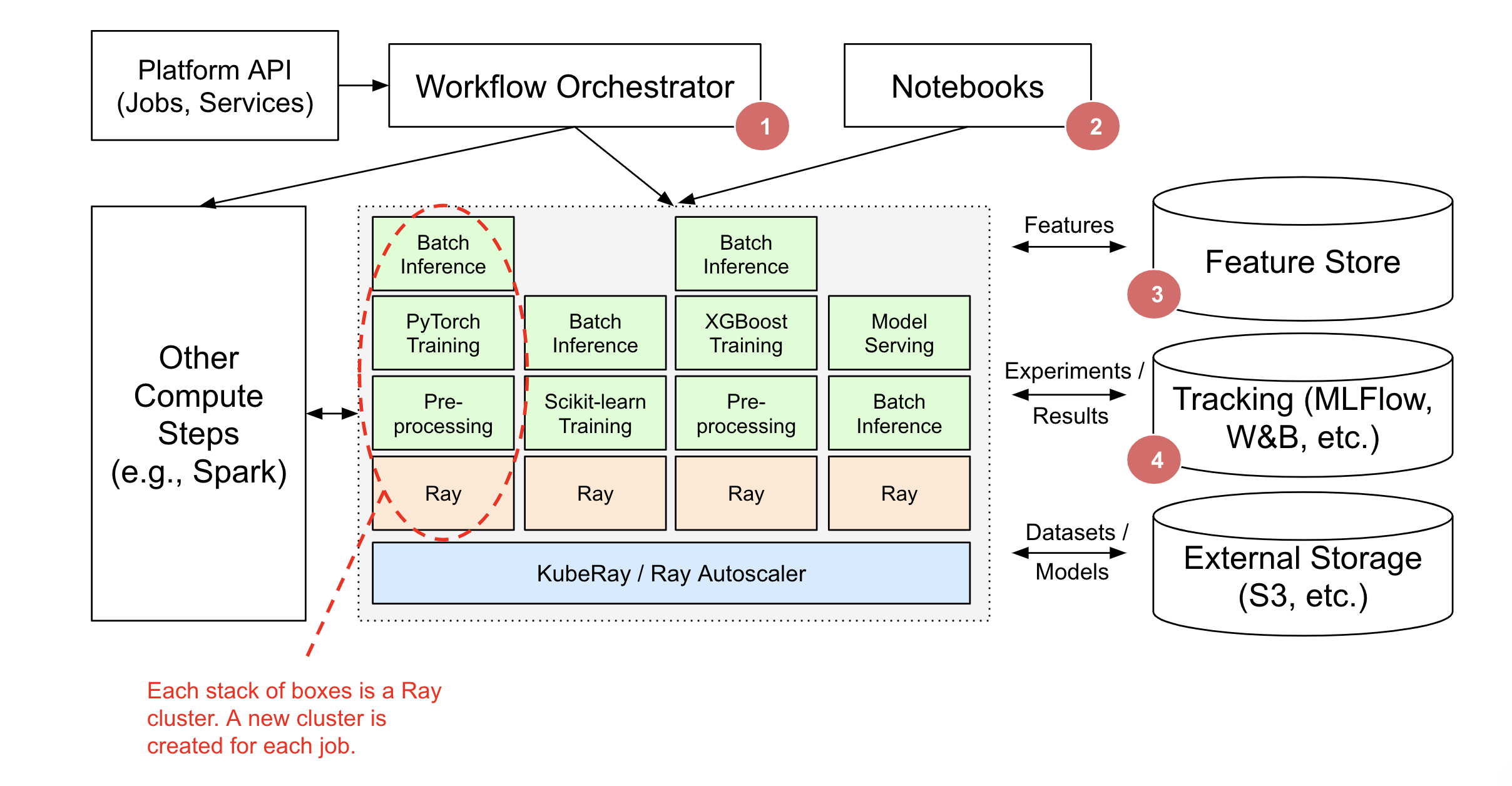
在上图中:
像 AirFlow、Oozie、SageMaker Pipelines 等这样的工作流编排器负责调度并创建 Ray 集群,以及运行 Ray 应用和服务。Ray 应用可能是更大编排工作流的一部分(例如,Spark ETL,然后在 Ray 上进行训练)。
任务图的轻量级编排可以在 Ray 内部完全处理。外部工作流编排器将很好地集成,但仅在运行非 Ray 步骤时才需要。
Ray 集群也可以为交互式使用而创建(例如,Jupyter 笔记本、Google Colab、Databricks 笔记本等)。
Ray Train、Data 和 Serve 提供了与 Feast 等特征存储的集成,用于训练和服务。
Ray Train 和 Tune 提供了与 MLFlow 和 Weights & Biases 等跟踪服务的集成。