放置组#
放置组允许用户在多个节点上原子性地保留一组资源(即,成组调度)。然后,它们可以用于为局部性(PACK)或分散(SPREAD)调度Ray任务和角色。放置组通常用于成组调度角色,但也支持任务。
以下是一些实际应用案例:
分布式机器学习训练:分布式训练(例如,Ray Train 和 Ray Tune)使用放置组API来实现群体调度。在这些设置中,一个试验的所有资源必须同时可用。群体调度是实现深度学习训练全有或全无调度的关键技术。
分布式训练中的容错:放置组可以用于配置容错。在 Ray Tune 中,将单个试验的相关资源打包在一起可能是有益的,这样节点故障只会影响少量试验。在支持弹性训练的库(例如,XGBoost-Ray)中,将资源分散到多个节点可以帮助确保即使某个节点失效,训练也能继续进行。
关键概念#
捆绑包#
一个 bundle 是“资源”的集合。它可以是单一资源,如 {"CPU": 1},或一组资源,如 {"CPU": 1, "GPU": 4}。bundle 是用于放置组的预留单元。“调度一个 bundle” 意味着我们找到一个适合该 bundle 的节点,并预留 bundle 指定的资源。一个 bundle 必须能够适应 Ray 集群中的单个节点。例如,如果你只有一个 8 CPU 的节点,而你有一个需要 {"CPU": 9} 的 bundle,这个 bundle 就无法被调度。
放置组#
放置组 从集群中预留资源。预留的资源只能被使用 PlacementGroupSchedulingStrategy 的任务或角色使用。
放置组由一组捆绑包表示。例如,
{"CPU": 1} * 4表示您希望保留 4 个包含 1 个 CPU 的捆绑包(即,它保留了 4 个 CPU)。然后,根据集群节点上的 放置策略 放置捆绑包。
创建放置组后,任务或角色可以根据放置组甚至单个捆绑包进行调度。
创建一个放置组(预留资源)#
你可以使用 ray.util.placement_group() 创建一个放置组。放置组接收一个捆绑列表和一个 放置策略。请注意,每个捆绑必须能够适应Ray集群中的单个节点。例如,如果你只有一个8 CPU的节点,并且你有一个需要 {"CPU": 9} 的捆绑,这个捆绑将无法被调度。
捆绑包通过字典列表指定,例如 [{'CPU': 1}, {'CPU': 1, 'GPU': 1}])。
CPU对应于在ray.remote中使用的num_cpus。GPU对应于在ray.remote中使用的num_gpus。memory对应于在ray.remote中使用的memory其他资源对应于
ray.remote中使用的resources``(例如,``ray.init(resources={"disk": 1})可以有一个{"disk": 1}的资源包)。
放置组调度是异步的。ray.util.placement_group 会立即返回。
from pprint import pprint
import time
# Import placement group APIs.
from ray.util.placement_group import (
placement_group,
placement_group_table,
remove_placement_group,
)
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
# Initialize Ray.
import ray
# Create a single node Ray cluster with 2 CPUs and 2 GPUs.
ray.init(num_cpus=2, num_gpus=2)
# Reserve a placement group of 1 bundle that reserves 1 CPU and 1 GPU.
pg = placement_group([{"CPU": 1, "GPU": 1}])
// Initialize Ray.
Ray.init();
// Construct a list of bundles.
Map<String, Double> bundle = ImmutableMap.of("CPU", 1.0);
List<Map<String, Double>> bundles = ImmutableList.of(bundle);
// Make a creation option with bundles and strategy.
PlacementGroupCreationOptions options =
new PlacementGroupCreationOptions.Builder()
.setBundles(bundles)
.setStrategy(PlacementStrategy.STRICT_SPREAD)
.build();
PlacementGroup pg = PlacementGroups.createPlacementGroup(options);
// Initialize Ray.
ray::Init();
// Construct a list of bundles.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
// Make a creation option with bundles and strategy.
ray::internal::PlacementGroupCreationOptions options{
false, "my_pg", bundles, ray::internal::PlacementStrategy::PACK};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
你可以使用以下两种API之一来阻止你的程序,直到放置组准备就绪:
# Wait until placement group is created.
ray.get(pg.ready(), timeout=10)
# You can also use ray.wait.
ready, unready = ray.wait([pg.ready()], timeout=10)
# You can look at placement group states using this API.
print(placement_group_table(pg))
// Wait for the placement group to be ready within the specified time(unit is seconds).
boolean ready = pg.wait(60);
Assert.assertTrue(ready);
// You can look at placement group states using this API.
List<PlacementGroup> allPlacementGroup = PlacementGroups.getAllPlacementGroups();
for (PlacementGroup group: allPlacementGroup) {
System.out.println(group);
}
// Wait for the placement group to be ready within the specified time(unit is seconds).
bool ready = pg.Wait(60);
assert(ready);
// You can look at placement group states using this API.
std::vector<ray::PlacementGroup> all_placement_group = ray::GetAllPlacementGroups();
for (const ray::PlacementGroup &group : all_placement_group) {
std::cout << group.GetName() << std::endl;
}
让我们验证放置组是否成功创建。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list placement-groups
======== List: 2023-04-07 01:15:05.682519 ========
Stats:
------------------------------
Total: 1
Table:
------------------------------
PLACEMENT_GROUP_ID NAME CREATOR_JOB_ID STATE
0 3cd6174711f47c14132155039c0501000000 01000000 CREATED
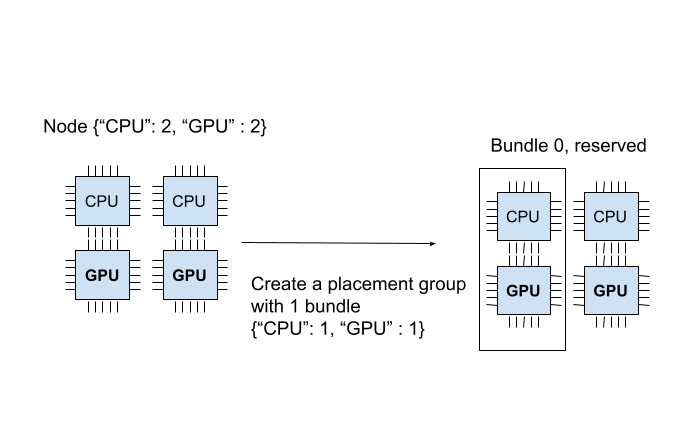
放置组已成功创建。在 {"CPU": 2, "GPU": 2} 资源中,放置组预留了 {"CPU": 1, "GPU": 1}。预留的资源只能在您使用放置组调度任务或角色时使用。下图展示了放置组预留的“1 CPU 和 1 GPU”捆绑包。
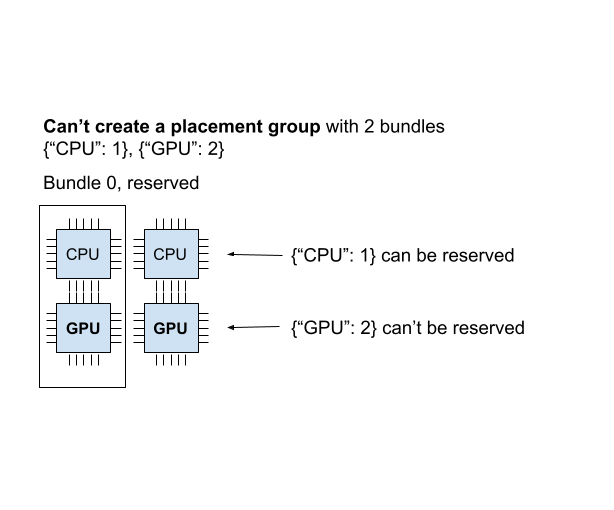
放置组是原子性创建的;如果一个捆绑包无法适应当前任何节点,整个放置组将未就绪,并且不会保留任何资源。为了说明,让我们创建另一个需要 ``{“CPU”:1}, {“GPU”: 2}``(2个捆绑包)的放置组。
# Cannot create this placement group because we
# cannot create a {"GPU": 2} bundle.
pending_pg = placement_group([{"CPU": 1}, {"GPU": 2}])
# This raises the timeout exception!
try:
ray.get(pending_pg.ready(), timeout=5)
except Exception as e:
print(
"Cannot create a placement group because "
"{'GPU': 2} bundle cannot be created."
)
print(e)
您可以验证新的放置组是否处于待创建状态。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list placement-groups
======== List: 2023-04-07 01:16:23.733410 ========
Stats:
------------------------------
Total: 2
Table:
------------------------------
PLACEMENT_GROUP_ID NAME CREATOR_JOB_ID STATE
0 3cd6174711f47c14132155039c0501000000 01000000 CREATED
1 e1b043bebc751c3081bddc24834d01000000 01000000 PENDING <---- the new placement group.
你也可以使用 ray status CLI 命令来验证 {"CPU": 1, "GPU": 2} 资源包无法被分配。
ray status
Resources
---------------------------------------------------------------
Usage:
0.0/2.0 CPU (0.0 used of 1.0 reserved in placement groups)
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/3.46GiB memory
0B/1.73GiB object_store_memory
Demands:
{'CPU': 1.0} * 1, {'GPU': 2.0} * 1 (PACK): 1+ pending placement groups <--- 1 placement group is pending creation.
当前集群有 {"CPU": 2, "GPU": 2}。我们已经创建了一个 {"CPU": 1, "GPU": 1} 的捆绑包,因此集群中只剩下 {"CPU": 1, "GPU": 1}。如果我们创建两个捆绑包 {"CPU": 1}, {"GPU": 2},我们可以成功创建第一个捆绑包,但无法调度第二个捆绑包。由于我们无法在集群上创建每个捆绑包,因此不会创建放置组,包括 {"CPU": 1} 捆绑包。
当无法以任何方式调度放置组时,它被称为“不可行”。想象一下,你调度了 {"CPU": 4} 的捆绑包,但你只有一个拥有2个CPU的节点。在你的集群中无法创建这个捆绑包。Ray Autoscaler 知道放置组,并自动扩展集群以确保待处理的组可以根据需要放置。
如果 Ray Autoscaler 无法提供资源来调度一个放置组,Ray 不会打印关于不可行组和使用这些组的任务和角色的警告。你可以从 仪表板或状态API 观察放置组的调度状态。
将任务和参与者调度到放置组(使用预留资源)#
在上一节中,我们创建了一个保留了 {"CPU": 1, "GPU: 1"} 的放置组,该放置组来自一个拥有2个CPU和2个GPU的节点。
现在让我们将一个执行者调度到放置组。你可以使用 options(scheduling_strategy=PlacementGroupSchedulingStrategy(...)) 将执行者或任务调度到放置组。
@ray.remote(num_cpus=1)
class Actor:
def __init__(self):
pass
def ready(self):
pass
# Create an actor to a placement group.
actor = Actor.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
)
).remote()
# Verify the actor is scheduled.
ray.get(actor.ready.remote(), timeout=10)
public static class Counter {
private int value;
public Counter(int initValue) {
this.value = initValue;
}
public int getValue() {
return value;
}
public static String ping() {
return "pong";
}
}
// Create GPU actors on a gpu bundle.
for (int index = 0; index < 1; index++) {
Ray.actor(Counter::new, 1)
.setPlacementGroup(pg, 0)
.remote();
}
class Counter {
public:
Counter(int init_value) : value(init_value){}
int GetValue() {return value;}
std::string Ping() {
return "pong";
}
private:
int value;
};
// Factory function of Counter class.
static Counter *CreateCounter() {
return new Counter();
};
RAY_REMOTE(&Counter::Ping, &Counter::GetValue, CreateCounter);
// Create GPU actors on a gpu bundle.
for (int index = 0; index < 1; index++) {
ray::Actor(CreateCounter)
.SetPlacementGroup(pg, 0)
.Remote(1);
}
备注
默认情况下,Ray 角色在调度时需要 1 个逻辑 CPU,但在调度后,它们不会获取任何 CPU 资源。换句话说,默认情况下,角色不能在零 CPU 节点上调度,但无限数量的角色可以在任何非零 CPU 节点上运行。因此,当使用默认资源要求和放置组调度角色时,放置组必须创建包含至少 1 个 CPU 的捆绑包(因为角色需要 1 个 CPU 进行调度)。然而,角色创建后,它不会消耗任何放置组资源。
为了避免任何意外,始终为角色明确指定资源需求。如果资源被明确指定,它们在调度时间和执行时间都是必需的。
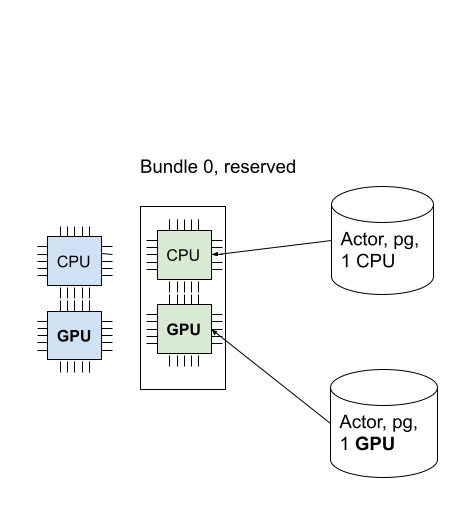
演员现在已安排!一个资源包可以被多个任务和演员使用(即,资源包与任务(或演员)之间是一对多的关系)。在这种情况下,由于演员使用了1个CPU,资源包中还剩下1个GPU。你可以通过CLI命令``ray status``来验证这一点。你可以看到1个CPU被放置组保留,并且1.0被使用(由我们创建的演员使用)。
ray status
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups) <---
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/4.29GiB memory
0B/2.00GiB object_store_memory
Demands:
(no resource demands)
你也可以使用 ray list actors 来验证角色是否已创建。
# This API is only available when you download Ray via `pip install "ray[default]"`
ray list actors --detail
- actor_id: b5c990f135a7b32bfbb05e1701000000
class_name: Actor
death_cause: null
is_detached: false
job_id: '01000000'
name: ''
node_id: b552ca3009081c9de857a31e529d248ba051a4d3aeece7135dde8427
pid: 8795
placement_group_id: d2e660ac256db230dbe516127c4a01000000 <------
ray_namespace: e5b19111-306c-4cd8-9e4f-4b13d42dff86
repr_name: ''
required_resources:
CPU_group_d2e660ac256db230dbe516127c4a01000000: 1.0
serialized_runtime_env: '{}'
state: ALIVE
由于还剩下1个GPU,让我们创建一个需要1个GPU的新actor。这次,我们还指定了``placement_group_bundle_index``。每个bundle在placement group中都有一个“索引”。例如,一个包含2个bundle的placement group [{"CPU": 1}, {"GPU": 1}] 有索引0的bundle {"CPU": 1} 和索引1的bundle {"GPU": 1}。由于我们只有一个bundle,所以我们只有索引0。如果你不指定bundle,actor(或任务)会被调度到一个具有未分配保留资源的随机bundle上。
@ray.remote(num_cpus=0, num_gpus=1)
class Actor:
def __init__(self):
pass
def ready(self):
pass
# Create a GPU actor on the first bundle of index 0.
actor2 = Actor.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_bundle_index=0,
)
).remote()
# Verify that the GPU actor is scheduled.
ray.get(actor2.ready.remote(), timeout=10)
我们成功调度了GPU执行者!下面的图像描述了两个执行者被调度到放置组中。
你也可以通过 ray status 命令来验证所有预留的资源是否都被使用。
ray status
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups)
1.0/2.0 GPU (1.0 used of 1.0 reserved in placement groups) <----
0B/4.29GiB memory
0B/2.00GiB object_store_memory
放置策略#
放置组提供的功能之一是在捆绑包之间添加放置约束。
例如,您可能希望将您的包打包到同一个节点,或者尽可能分散到多个节点。您可以通过 strategy 参数指定策略。这样,您可以确保您的参与者和任务可以根据某些放置约束进行调度。
下面的示例创建了一个包含2个束的放置组,使用PACK策略;这两个束必须创建在同一个节点上。请注意,这是一个软策略。如果束不能被打包到一个节点中,它们将被分散到其他节点。如果你想避免这个问题,可以使用`STRICT_PACK`策略,如果放置要求不能满足,则无法创建放置组。
# Reserve a placement group of 2 bundles
# that have to be packed on the same node.
pg = placement_group([{"CPU": 1}, {"GPU": 1}], strategy="PACK")
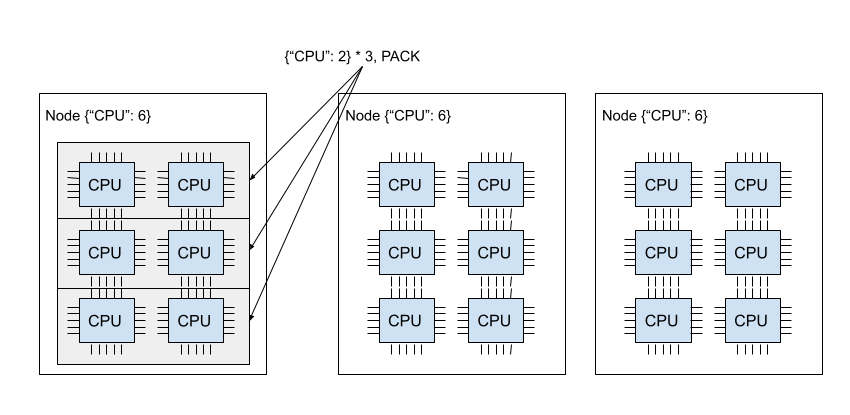
下图展示了 PACK 策略。三个 {"CPU": 2} 捆绑包位于同一个节点中。
下图展示了SPREAD策略。三个 {"CPU": 2} 的捆绑包分别位于三个不同的节点上。
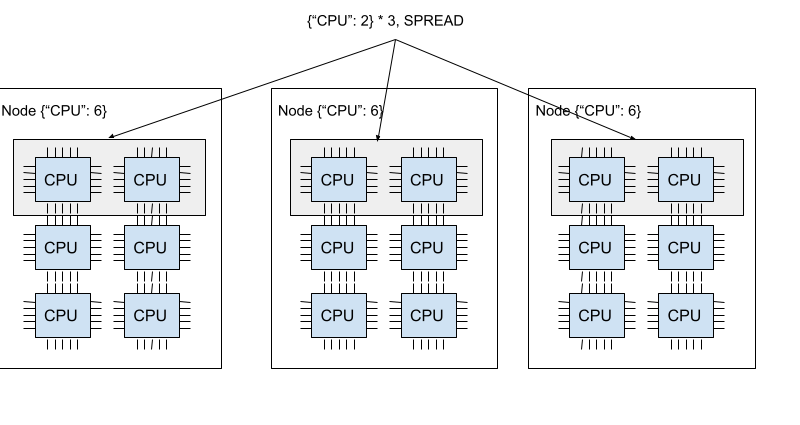
Ray 支持四种放置组策略。默认的调度策略是 PACK。
STRICT_PACK
所有捆绑包必须放置在集群的单个节点上。当你想要最大化局部性时,请使用此策略。
包
所有提供的包都是基于尽力而为的原则打包到一个节点上。如果严格打包不可行(即,某些包不适合该节点),可以将包放置到其他节点上。
STRICT_SPREAD
每个捆绑包必须在单独的节点上调度。
传播
每个捆绑包都会尽力分散到不同的节点上。如果严格分散不可行,捆绑包可以放置在重叠的节点上。
移除放置组(释放预留资源)#
默认情况下,放置组的生存期与创建它的驱动程序的作用域相同(除非你将其设为 分离的放置组)。当从 分离的执行体 创建放置组时,生存期与分离的执行体的作用域相同。在 Ray 中,驱动程序是调用 ray.init 的 Python 脚本。
从放置组中保留的资源(捆绑)在创建放置组的驱动程序或分离的执行者退出时会自动释放。要手动释放保留的资源,请使用 remove_placement_group API 删除放置组(这也是一个异步API)。
备注
当你移除放置组时,仍然使用保留资源的演员或任务将被强制终止。
# This API is asynchronous.
remove_placement_group(pg)
# Wait until placement group is killed.
time.sleep(1)
# Check that the placement group has died.
pprint(placement_group_table(pg))
"""
{'bundles': {0: {'GPU': 1.0}, 1: {'CPU': 1.0}},
'name': 'unnamed_group',
'placement_group_id': '40816b6ad474a6942b0edb45809b39c3',
'state': 'REMOVED',
'strategy': 'PACK'}
"""
PlacementGroups.removePlacementGroup(placementGroup.getId());
PlacementGroup removedPlacementGroup = PlacementGroups.getPlacementGroup(placementGroup.getId());
Assert.assertEquals(removedPlacementGroup.getState(), PlacementGroupState.REMOVED);
ray::RemovePlacementGroup(placement_group.GetID());
ray::PlacementGroup removed_placement_group = ray::GetPlacementGroup(placement_group.GetID());
assert(removed_placement_group.GetState(), ray::PlacementGroupState::REMOVED);
观察和调试放置组#
Ray 提供了几种有用的工具来检查放置组状态和资源使用情况。
Ray Status 是一个用于查看放置组资源使用情况和调度资源需求的CLI工具。
Ray Dashboard 是一个用于检查放置组状态的UI工具。
Ray State API 是一个用于检查放置组状态的CLI。
CLI 命令 ray status 提供了集群的自动扩展状态。它提供了未调度放置组的“资源需求”以及资源预留状态。
Resources
---------------------------------------------------------------
Usage:
1.0/2.0 CPU (1.0 used of 1.0 reserved in placement groups)
0.0/2.0 GPU (0.0 used of 1.0 reserved in placement groups)
0B/4.29GiB memory
0B/2.00GiB object_store_memory
The dashboard job view 提供了放置组表,显示了放置组的调度状态和元数据。
备注
Ray 仪表板仅在安装 Ray 时使用 pip install "ray[default]" 才可用。
Ray 状态 API 是一个用于检查 Ray 资源(任务、角色、放置组等)状态的 CLI 工具。
ray list placement-groups 提供了放置组的元数据和调度状态。ray list placement-groups --detail 提供了更详细的统计信息和调度状态。
备注
State API 仅在您使用 pip install "ray[default]" 安装 Ray 时可用
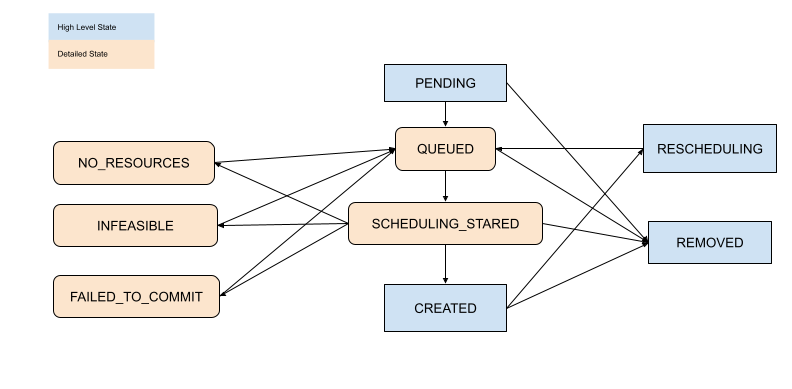
检查放置组调度状态#
使用上述工具,您可以查看放置组的状态。状态的定义在以下文件中指定:
[高级] 子任务和角色#
默认情况下,子执行体和任务不共享父执行体使用的相同放置组。要自动将子执行体或任务调度到相同的放置组,请将 placement_group_capture_child_tasks 设置为 True。
import ray
from ray.util.placement_group import placement_group
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
ray.init(num_cpus=2)
# Create a placement group.
pg = placement_group([{"CPU": 2}])
ray.get(pg.ready())
@ray.remote(num_cpus=1)
def child():
import time
time.sleep(5)
@ray.remote(num_cpus=1)
def parent():
# The child task is scheduled to the same placement group as its parent,
# although it didn't specify the PlacementGroupSchedulingStrategy.
ray.get(child.remote())
# Since the child and parent use 1 CPU each, the placement group
# bundle {"CPU": 2} is fully occupied.
ray.get(
parent.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg, placement_group_capture_child_tasks=True
)
).remote()
)
Java API 尚未实现。
当 placement_group_capture_child_tasks 为 True 时,但你不希望将子任务和执行者调度到同一个放置组,请指定 PlacementGroupSchedulingStrategy(placement_group=None)。
@ray.remote
def parent():
# In this case, the child task isn't
# scheduled with the parent's placement group.
ray.get(
child.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(placement_group=None)
).remote()
)
# This times out because we cannot schedule the child task.
# The cluster has {"CPU": 2}, and both of them are reserved by
# the placement group with a bundle {"CPU": 2}. Since the child shouldn't
# be scheduled within this placement group, it cannot be scheduled because
# there's no available CPU resources.
try:
ray.get(
parent.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg, placement_group_capture_child_tasks=True
)
).remote(),
timeout=5,
)
except Exception as e:
print("Couldn't create a child task!")
print(e)
警告
对于给定的actor,placement_group_capture_child_tasks 的值不会从其父actor继承。如果你正在创建深度大于1的嵌套actor,并且所有actor都应该使用相同的placement group,你应该为每个actor显式设置 placement_group_capture_child_tasks。
[高级] 命名放置组#
一个放置组可以被赋予一个全局唯一的名称。这允许你从Ray集群中的任何作业中检索放置组。如果你无法直接将放置组句柄传递给需要它的actor或任务,或者如果你试图访问由另一个驱动程序启动的放置组,这会很有用。请注意,如果放置组的生存期不是`detached`,它仍然会被销毁。
# first_driver.py
# Create a placement group with a global name.
pg = placement_group([{"CPU": 1}], name="global_name")
ray.get(pg.ready())
# second_driver.py
# Retrieve a placement group with a global name.
pg = ray.util.get_placement_group("global_name")
// Create a placement group with a unique name.
Map<String, Double> bundle = ImmutableMap.of("CPU", 1.0);
List<Map<String, Double>> bundles = ImmutableList.of(bundle);
PlacementGroupCreationOptions options =
new PlacementGroupCreationOptions.Builder()
.setBundles(bundles)
.setStrategy(PlacementStrategy.STRICT_SPREAD)
.setName("global_name")
.build();
PlacementGroup pg = PlacementGroups.createPlacementGroup(options);
pg.wait(60);
...
// Retrieve the placement group later somewhere.
PlacementGroup group = PlacementGroups.getPlacementGroup("global_name");
Assert.assertNotNull(group);
// Create a placement group with a globally unique name.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
ray::PlacementGroupCreationOptions options{
true/*global*/, "global_name", bundles, ray::PlacementStrategy::STRICT_SPREAD};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
pg.Wait(60);
...
// Retrieve the placement group later somewhere.
ray::PlacementGroup group = ray::GetGlobalPlacementGroup("global_name");
assert(!group.Empty());
我们还支持C++中的非全局命名放置组,这意味着放置组名称仅在作业内有效,无法从另一个作业访问。
// Create a placement group with a job-scope-unique name.
std::vector<std::unordered_map<std::string, double>> bundles{{{"CPU", 1.0}}};
ray::PlacementGroupCreationOptions options{
false/*non-global*/, "non_global_name", bundles, ray::PlacementStrategy::STRICT_SPREAD};
ray::PlacementGroup pg = ray::CreatePlacementGroup(options);
pg.Wait(60);
...
// Retrieve the placement group later somewhere in the same job.
ray::PlacementGroup group = ray::GetPlacementGroup("non_global_name");
assert(!group.Empty());
[高级] 分离放置组#
默认情况下,放置组的生存期属于驱动程序和执行程序。
如果放置组是从驱动程序创建的,那么当驱动程序终止时,它也会被销毁。
如果它是由一个分离的actor创建的,当分离的actor被杀死时,它也会被杀死。
要保持放置组在任何作业或分离的执行者中存活,请指定 lifetime="detached"。例如:
# driver_1.py
# Create a detached placement group that survives even after
# the job terminates.
pg = placement_group([{"CPU": 1}], lifetime="detached", name="global_name")
ray.get(pg.ready())
生命周期参数尚未在Java API中实现。
让我们终止当前的脚本并启动一个新的 Python 脚本。调用 ray list placement-groups,你可以看到放置组没有被移除。
请注意,生命周期选项与名称是分离的。如果我们只指定了名称而没有指定 lifetime="detached",那么放置组只能在原始驱动程序仍在运行时才能被检索。建议在创建分离的放置组时始终指定名称。
[高级] 容错#
在死节点上重新调度捆绑包#
如果包含某个放置组中的一些束的节点死亡,GCS(即我们尝试再次保留资源)会将所有束重新调度到不同的节点上。这意味着放置组的初始创建是“原子的”,但一旦创建,就可能存在部分放置组。重新调度束的调度优先级高于其他放置组调度。
为部分丢失的捆绑包提供资源#
如果没有足够的资源来调度部分丢失的捆绑包,放置组将等待,假设 Ray Autoscaler 会启动一个新节点以满足资源需求。如果无法提供额外的资源(例如,您不使用 Autoscaler 或 Autoscaler 达到资源限制),放置组将无限期地保持部分创建状态。
使用捆绑包的参与者和任务的容错性#
使用捆绑包(保留资源)的参与者和任务在捆绑包恢复后,会根据其 容错策略 重新调度。