备注
Ray 2.10.0 引入了 RLlib 的“新 API 栈”的 alpha 阶段。Ray 团队计划将算法、示例脚本和文档迁移到新的代码库中,从而在 Ray 3.0 之前的后续小版本中逐步替换“旧 API 栈”(例如,ModelV2、Policy、RolloutWorker)。
然而,请注意,到目前为止,只有 PPO(单代理和多代理)和 SAC(仅单代理)支持“新 API 堆栈”,并且默认情况下继续使用旧 API 运行。您可以继续使用现有的自定义(旧堆栈)类。
请参阅此处 以获取有关如何使用新API堆栈的更多详细信息。
高级 Python API#
自定义训练工作流程#
在 基本训练示例 中,Tune 将在每次训练迭代中调用您的算法的 train() 方法,并报告新的训练结果。有时,希望完全控制训练过程,但仍希望在 Tune 中运行。Tune 支持 自定义可训练函数,可用于实现 自定义训练工作流程(示例)。
课程学习#
在课程学习中,您可以在训练过程中设置不同难度的环境。这种设置允许算法通过与越来越困难的阶段进行交互和探索,逐步学习如何解决实际和最终的问题。通常,这种课程从设置环境为简单级别开始,然后随着训练的进行,逐渐过渡到更难解决的难度。有关如何进行课程学习的另一个示例,请参阅 强化学习代理的反向课程生成 博客文章。
RLlib 的算法和自定义回调 API 允许实现任何任意的课程。这个 示例脚本 介绍了你需要理解的基本概念。
首先,定义一些环境选项。这个例子使用了 FrozenLake-v1 环境,这是一个网格世界,其地图是完全可定制的。三个不同难度的任务通过稍微不同的地图来表示,代理必须在这些地图中导航。
ENV_OPTIONS = {
"is_slippery": False,
# Limit the number of steps the agent is allowed to make in the env to
# make it almost impossible to learn without the curriculum.
"max_episode_steps": 16,
}
# Our 3 tasks: 0=easiest, 1=medium, 2=hard
ENV_MAPS = [
# 0
[
"SFFHFFFH",
"FFFHFFFF",
"FFGFFFFF",
"FFFFFFFF",
"HFFFFFFF",
"HHFFFFHF",
"FFFFFHHF",
"FHFFFFFF",
],
# 1
[
"SFFHFFFH",
"FFFHFFFF",
"FFFFFFFF",
"FFFFFFFF",
"HFFFFFFF",
"HHFFGFHF",
"FFFFFHHF",
"FHFFFFFF",
],
# 2
[
"SFFHFFFH",
"FFFHFFFF",
"FFFFFFFF",
"FFFFFFFF",
"HFFFFFFF",
"HHFFFFHF",
"FFFFFHHF",
"FHFFFFFG",
],
]
然后,定义控制课程的核心部分,这是一个自定义回调类,重写 on_train_result()。
import ray
from ray import tune
from ray.rllib.agents.callbacks import DefaultCallbacks
class MyCallbacks(DefaultCallbacks):
def on_train_result(self, algorithm, result, **kwargs):
if result["env_runners"]["episode_return_mean"] > 200:
task = 2
elif result["env_runners"]["episode_return_mean"] > 100:
task = 1
else:
task = 0
algorithm.env_runner_group.foreach_worker(
lambda ev: ev.foreach_env(
lambda env: env.set_task(task)))
ray.init()
tune.Tuner(
"PPO",
param_space={
"env": YourEnv,
"callbacks": MyCallbacks,
},
).fit()
全球协调#
有时,需要在由 RLlib 管理的不同进程中的代码之间进行协调。例如,维护某个变量的全局平均值,或集中控制策略使用的超参数,可能会很有用。Ray 通过 命名角色 提供了一种通用方式来实现这一点(了解更多关于 Ray 角色)。这些角色被分配了一个全局名称,并且可以通过这些名称检索到它们的句柄。作为一个例子,考虑维护一个由环境递增并定期从驱动程序读取的共享全局计数器:
import ray
@ray.remote
class Counter:
def __init__(self):
self.count = 0
def inc(self, n):
self.count += n
def get(self):
return self.count
# on the driver
counter = Counter.options(name="global_counter").remote()
print(ray.get(counter.get.remote())) # get the latest count
# in your envs
counter = ray.get_actor("global_counter")
counter.inc.remote(1) # async call to increment the global count
Ray actors 提供了高水平的性能,因此在更复杂的情况下,它们可以用来实现诸如参数服务器和全归约等通信模式。
回调和自定义指标#
您可以提供在策略评估期间调用的回调函数。这些回调函数可以访问当前 episode 的状态。某些回调函数,如 on_postprocess_trajectory、on_sample_end 和 on_train_result,也是应用自定义后处理到中间数据或结果的地方。
用户定义的状态可以存储在 episode 的 episode.user_data 字典中,并通过将值保存到 episode.custom_metrics 字典中来报告自定义标量指标。这些自定义指标会被聚合并作为训练结果的一部分进行报告。有关完整示例,请查看 此示例脚本 和 这些单元测试用例。
小技巧
你可以通过检查 RolloutWorker 是否处于评估模式,来创建在每次评估回合中运行的自定义逻辑,通过访问 worker.policy_config["in_evaluation"]。然后,你可以在 DefaultCallbacks 的子类的 on_episode_start() 或 on_episode_end() 中实现这个检查。对于在评估运行前后执行回调,我们提供了 on_evaluate_start() 和 on_evaluate_end()。
点击此处查看 DefaultCallbacks 类的完整API
- class ray.rllib.algorithms.callbacks.DefaultCallbacks[源代码]#
RLlib 回调的抽象基类(类似于 Keras 回调)。
这些回调可以用于自定义指标和自定义后处理。
默认情况下,所有这些回调都是空操作。要配置自定义训练回调,请子类化 DefaultCallbacks,然后在算法配置中设置 {“callbacks”: YourCallbacksClass}。
- on_algorithm_init(*, algorithm: Algorithm, metrics_logger: MetricsLogger | None = None, **kwargs) None[源代码]#
当一个新的算法实例完成设置时运行的回调。
此方法在所有初始化完成后,在实际训练开始之前,在 Algorithm.setup() 结束时被调用。
- 参数:
algorithm – 对算法实例的引用。
metrics_logger –
Algorithm内部的 MetricsLogger 对象。可以在算法初始化后用于记录自定义指标。kwargs – 向前兼容占位符。
- on_workers_recreated(*, algorithm: Algorithm, worker_set: EnvRunnerGroup, worker_ids: List[int], is_evaluation: bool, **kwargs) None[源代码]#
在一个或多个工作进程被重新创建后运行的回调。
您可以通过以下代码片段访问(并更改)相关的工作者(们),这段代码位于您对此方法的自定义重写内部:
请注意,算法中
self.env_runner_group和self.eval_env_runner_group内的任何“worker”都是 EnvRunner 的子类的实例。class MyCallbacks(DefaultCallbacks): def on_workers_recreated( self, *, algorithm, worker_set, worker_ids, is_evaluation, **kwargs, ): # Define what you would like to do on the recreated # workers: def func(w): # Here, we just set some arbitrary property to 1. if is_evaluation: w._custom_property_for_evaluation = 1 else: w._custom_property_for_training = 1 # Use the `foreach_workers` method of the worker set and # only loop through those worker IDs that have been restarted. # Note that we set `local_worker=False` to NOT include it (local # workers are never recreated; if they fail, the entire Algorithm # fails). worker_set.foreach_worker( func, remote_worker_ids=worker_ids, local_worker=False, )
- 参数:
algorithm – 对算法实例的引用。
worker_set – 问题中的工作者所在的 EnvRunnerGroup 对象。你可以使用
worker_set.foreach_worker(remote_worker_ids=..., local_worker=False)方法调用来在重新创建的(远程)工作者上执行自定义代码。请注意,本地工作者永远不会被重新创建,因为这会导致算法崩溃。worker_ids – 已重新创建的(远程)工作者ID列表。
is_evaluation – 无论
worker_set是否是评估 EnvRunnerGroup(位于Algorithm.eval_env_runner_group)。
- on_checkpoint_loaded(*, algorithm: Algorithm, **kwargs) None[源代码]#
当算法从检查点加载新状态时运行的回调。
此方法在
Algorithm.load_checkpoint()结束时被调用。- 参数:
algorithm – 对算法实例的引用。
kwargs – 向前兼容占位符。
- on_create_policy(*, policy_id: str, policy: Policy) None[源代码]#
每当向算法添加新策略时运行的回调函数。
- 参数:
policy_id – 新创建策略的ID。
policy – 刚刚创建的策略。
- on_environment_created(*, env_runner: EnvRunner, metrics_logger: MetricsLogger | None = None, env: gymnasium.Env, env_context: EnvContext, **kwargs) None[源代码]#
当创建了一个新的环境对象时运行的回调函数。
注意:这仅适用于新的API堆栈。使用的环境通常是一个gym.Env(或更具体地说是一个gym.vector.Env)。
- 参数:
env_runner – 对当前 EnvRunner 实例的引用。
metrics_logger –
env_runner内部的 MetricsLogger 对象。可以在环境创建后用于记录自定义指标。env – 在
env_runner上创建的环境对象。这通常是一个 gym.Env(或 gym.vector.Env)对象。env_context – 传递给
gym.make()调用的EnvContext对象作为 kwargs(以及传递给 gym.Env 的config)。它应该包含所有配置键/值对以及 EnvContext 典型的属性:worker_index、num_workers和remote。kwargs – 向前兼容占位符。
- on_sub_environment_created(*, worker: EnvRunner, sub_environment: Any | gymnasium.Env, env_context: EnvContext, env_index: int | None = None, **kwargs) None[源代码]#
当创建了新的子环境时运行的回调。
此方法在每个子环境(通常是一个 gym.Env)被创建、验证(RLlib 内置验证 + 可能通过重写
Algorithm.validate_env()实现的定制验证函数)、包装(例如视频包装器)和种子化之后调用。- 参数:
worker – 对当前部署工作者的引用。
sub_environment – 已创建的子环境实例。这通常是一个 gym.Env 对象。
env_context – 传递给环境构造函数的
EnvContext对象。env_index – 已创建的子环境的索引(在 BaseEnv 的子环境向量中)。
kwargs – 向前兼容占位符。
- on_episode_created(*, episode: SingleAgentEpisode | MultiAgentEpisode | Episode | EpisodeV2, worker: EnvRunner | None = None, env_runner: EnvRunner | None = None, metrics_logger: MetricsLogger | None = None, base_env: BaseEnv | None = None, env: gymnasium.Env | None = None, policies: Dict[str, Policy] | None = None, rl_module: RLModule | None = None, env_index: int, **kwargs) None[源代码]#
当新的一集被创建时(但尚未开始!)运行的回调。
此方法在创建新的 Episode(V2)(旧堆栈)或 MultiAgentEpisode 实例后被调用。这发生在 RLlib 调用相应子环境(通常是 gym.Env)的
reset()之前。注意,目前在新API堆栈和单一代理模式下,此回调不会被调用。
Episode(V2)/MultiAgentEpisode 创建: 调用此回调。
各自的子环境 (gym.Env) 是
reset()。回调
on_episode_start被调用。开始遍历子环境/情节。
- 参数:
episode – 新创建的剧集。在新 API 栈中,这将是一个 MultiAgentEpisode 对象。在旧 API 栈中,这将是一个 Episode 或 EpisodeV2 对象。这是即将在即将到来的
env.reset()中开始的剧集。只有在这次重置调用之后,on_episode_start回调才会被调用。env_runner – 替换
worker参数。对当前 EnvRunner 的引用。metrics_logger –
env_runner中的 MetricsLogger 对象。可以在创建 Episode 后用于记录自定义指标。env – 替换
base_env参数。gym.Env(新API栈)或RLlib BaseEnv(旧API栈)运行该片段。在旧栈中,可以通过调用base_env.get_sub_environments()来获取底层子环境对象。rl_module – 替换
policies参数。可以是 RLModule(新 API 栈)或一个映射策略 ID 到策略对象的字典(旧栈)。在单代理模式下,将只有一个策略/RLModule 位于rl_module["default_policy"]键下。env_index – 即将被重置的子环境的索引(在 BaseEnv 的子环境向量中)。
kwargs – 向前兼容占位符。
- on_episode_start(*, episode: SingleAgentEpisode | MultiAgentEpisode | Episode | EpisodeV2, env_runner: EnvRunner | None = None, metrics_logger: MetricsLogger | None = None, env: gymnasium.Env | None = None, env_index: int, rl_module: RLModule | None = None, worker: EnvRunner | None = None, base_env: BaseEnv | None = None, policies: Dict[str, Policy] | None = None, **kwargs) None[源代码]#
在剧集开始后立即运行的回调。
此方法在 EnvRunner 调用
env.reset()重置 SingleAgentEpisode 或 MultiAgentEpisode 实例后被调用。单/多智能体回合创建:调用
on_episode_created()。各自的子环境 (gym.Env) 是
reset()。单/多智能体回合开始:调用此回调。
开始遍历子环境/情节。
- 参数:
episode – 刚刚开始(在
env.reset()之后)的 SingleAgentEpisode 或 MultiAgentEpisode 对象。env_runner – 对运行环境和剧集的 EnvRunner 的引用。
metrics_logger –
env_runner中的 MetricsLogger 对象。可以在环境/回合步进期间用于记录自定义指标。env – 运行启动的剧集的 gym.Env 或 gym.vector.Env 对象。
env_index – 即将被重置的子环境的索引(在 BaseEnv 的子环境向量中)。
rl_module – 用于计算环境步进动作的 RLModule。在单智能体设置中,这是一个(单智能体)RLModule,在多智能体设置中,这将是一个 MultiRLModule。
kwargs – 向前兼容占位符。
- on_episode_step(*, episode: SingleAgentEpisode | MultiAgentEpisode | Episode | EpisodeV2, env_runner: EnvRunner | None = None, metrics_logger: MetricsLogger | None = None, env: gymnasium.Env | None = None, env_index: int, rl_module: RLModule | None = None, worker: EnvRunner | None = None, base_env: BaseEnv | None = None, policies: Dict[str, Policy] | None = None, **kwargs) None[源代码]#
在每个情节步骤调用(在动作被记录之后)。
请注意,在新API栈中,此回调函数也会在剧集的最后一步之后被调用,这意味着当
env.step()调用返回 terminated/truncated 为 True 时,但仍会提供未最终确定的剧集对象(意味着数据尚未转换为numpy数组)。这个回调被调用的确切时间是在
env.step([action])之后,并且也是在这次步骤的结果(观察、奖励、终止、截断、信息)已经被记录到给定的episode对象之后。- 参数:
episode – 刚刚执行的 SingleAgentEpisode 或 MultiAgentEpisode 对象(在
env.step()之后,并且在返回的 obs、rewards 等已记录到 episode 对象之后)。env_runner – 对运行环境和剧集的 EnvRunner 的引用。
metrics_logger –
env_runner中的 MetricsLogger 对象。可以在环境/回合步进期间用于记录自定义指标。env – 运行启动的剧集的 gym.Env 或 gym.vector.Env 对象。
env_index – 刚刚步进的子环境的索引。
rl_module – 用于计算环境步进动作的 RLModule。在单智能体设置中,这是一个(单智能体)RLModule,在多智能体设置中,这将是一个 MultiRLModule。
kwargs – 向前兼容占位符。
- on_episode_end(*, episode: SingleAgentEpisode | MultiAgentEpisode | Episode | EpisodeV2, env_runner: EnvRunner | None = None, metrics_logger: MetricsLogger | None = None, env: gymnasium.Env | None = None, env_index: int, rl_module: RLModule | None = None, worker: EnvRunner | None = None, base_env: BaseEnv | None = None, policies: Dict[str, Policy] | None = None, **kwargs) None[源代码]#
在剧集结束时调用(在终止/截断被记录后)。
这个回调被调用的确切时间是在
env.step([action])之后,并且也是在这次步骤的结果(观察、奖励、终止、截断、信息)已经被记录到给定的episode对象之后,其中终止或截断为 True:环境被推进:
final_obs, rewards, ... = env.step([action])步骤结果被记录
episode.add_env_step(final_obs, rewards)回调
on_episode_step被触发。另一个 env-to-module 连接器调用被发起(尽管我们不再需要任何 RLModule 前向传递)。我们进行这个额外的调用是为了确保,如果用户使用连接器管道来处理观察结果(并将它们写回到 episode 中),episode 对象已经包含了所有观察结果——即使是终端观察结果——都得到了适当的处理。
—> 这个回调
on_episode_end()被触发。 <—该集已完成(即观察/奖励/动作等列表已转换为numpy数组)。
- 参数:
episode – 终止/截断的 SingleAgent 或 MultiAgentEpisode 对象(在返回 terminated=True 或 truncated=True 的
env.step()之后,并且在返回的 obs、rewards 等已记录到 episode 对象之后)。请注意,此方法仍在 episode 对象最终确定之前调用,这意味着其所有时间步数据仍以单个时间步数据的列表形式存在。env_runner – 对运行环境和剧集的 EnvRunner 的引用。
metrics_logger –
env_runner中的 MetricsLogger 对象。可以在环境/回合步进期间用于记录自定义指标。env – 运行启动的剧集的 gym.Env 或 gym.vector.Env 对象。
env_index – 刚刚终止或截断的子环境的索引。
rl_module – 用于计算环境步进动作的 RLModule。在单智能体设置中,这是一个(单智能体)RLModule,在多智能体设置中,这将是一个 MultiRLModule。
kwargs – 向前兼容占位符。
- on_evaluate_start(*, algorithm: Algorithm, metrics_logger: MetricsLogger | None = None, **kwargs) None[源代码]#
评估开始前的回调。
此方法在 Algorithm.evaluate() 开始时被调用。
- 参数:
algorithm – 对算法实例的引用。
metrics_logger –
Algorithm中的 MetricsLogger 对象。可以在运行下一轮评估之前用于记录自定义指标。kwargs – 向前兼容占位符。
- on_evaluate_end(*, algorithm: Algorithm, metrics_logger: MetricsLogger | None = None, evaluation_metrics: dict, **kwargs) None[源代码]#
评估完成后运行。
在 Algorithm.evaluate() 结束时运行。
- 参数:
algorithm – 对算法实例的引用。
metrics_logger –
Algorithm内部的 MetricsLogger 对象。可以在最近的评估轮次后用于记录自定义指标。evaluation_metrics – 从 algorithm.evaluate() 返回的结果字典。你可以修改这个对象以添加额外的指标。
kwargs – 向前兼容占位符。
- on_postprocess_trajectory(*, worker: EnvRunner, episode: Episode, agent_id: Any, policy_id: str, policies: Dict[str, Policy], postprocessed_batch: SampleBatch, original_batches: Dict[Any, Tuple[Policy, SampleBatch]], **kwargs) None[源代码]#
在策略的 postprocess_fn 调用后立即调用。
您可以使用此回调对策略进行额外的后处理,包括在多智能体设置中查看其他智能体的轨迹数据。
- 参数:
worker – 对当前部署工作者的引用。
episode – 剧集对象。
agent_id – 当前代理的ID。
policy_id – 代理当前策略的ID。
policies – 字典映射策略ID到策略对象。在单代理模式下,将只有一个“default_policy”。
postprocessed_batch – 该代理的样本批次经过后处理。你可以修改这个对象以应用你自己的轨迹后处理。
original_batches – 字典映射代理ID到它们的未后处理轨迹数据。你不应该修改这个对象。
kwargs – 向前兼容占位符。
- on_sample_end(*, env_runner: EnvRunner | None = None, metrics_logger: MetricsLogger | None = None, samples: SampleBatch | List[SingleAgentEpisode | MultiAgentEpisode], worker: EnvRunner | None = None, **kwargs) None[源代码]#
在
EnvRunner.sample()结束时调用。- 参数:
env_runner – 对当前 EnvRunner 对象的引用。
metrics_logger –
env_runner中的 MetricsLogger 对象。可以在环境/回合步进期间用于记录自定义指标。samples – 待返回的批次。您可以修改此对象以更改生成的样本。
kwargs – 向前兼容占位符。
- on_learn_on_batch(*, policy: Policy, train_batch: SampleBatch, result: dict, **kwargs) None[源代码]#
在 Policy.learn_on_batch() 开始时调用。
注意:这被称为在通过
pad_batch_to_sequences_of_same_size进行0填充之前。另外请注意,如果框架是 tf1,由于 tf1 静态图会将它误认为是输入字典的一部分,因此在回调中的 train_batch 上将无法使用 SampleBatch.INFOS 列。不过,对于 tf2 和 torch 框架,它是可用的。
- 参数:
policy – 对当前策略对象的引用。
train_batch – 要训练的样本批次。你可以修改此对象以改变生成的样本。
result – 一个用于添加自定义指标的结果字典。
kwargs – 向前兼容占位符。
- on_train_result(*, algorithm: Algorithm, metrics_logger: MetricsLogger | None = None, result: dict, **kwargs) None[源代码]#
在 Algorithm.train() 结束时调用。
- 参数:
algorithm – 当前算法实例。
metrics_logger – Algorithm 内部的 MetricsLogger 对象。可以在训练结果可用后用于记录自定义指标。
result – 从 Algorithm.train() 调用返回的结果字典。你可以修改这个对象以添加额外的指标。
kwargs – 向前兼容占位符。
链式回调#
使用 make_multi_callbacks() 工具将多个回调链接在一起。
- ray.rllib.algorithms.callbacks.make_multi_callbacks(callback_class_list: List[Type[DefaultCallbacks]]) DefaultCallbacks[源代码]#
允许将多个子回调组合成一个新的回调类。
生成的 DefaultCallbacks 在调用时会调用所有子回调的回调。
config.callbacks(make_multi_callbacks([ MyCustomStatsCallbacks, MyCustomVideoCallbacks, MyCustomTraceCallbacks, .... ]))
- 参数:
callback_class_list – 要嵌入到待返回类中的 DefaultCallbacks 子类的列表。这些子类的所有实现方法将按给定顺序调用。
- 返回:
一个结合了所有给定子类的 DefaultCallbacks 子类。
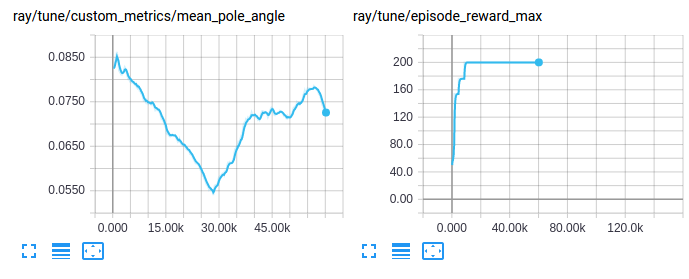
可视化自定义指标#
自定义指标可以像其他训练结果一样被访问和可视化:
自定义探索行为#
RLlib 提供了一个统一的顶级 API 来配置和自定义代理的探索行为,包括从分布中采样动作的决策(如何以及是否)(随机或确定性)。可以使用内置的探索类(参见 这个包)来完成设置,这些类在 AlgorithmConfig().env_runners(..) 中指定(并进一步配置)。除了使用可用的类之一外,还可以对这些内置类进行子类化,向其添加自定义行为,并在配置中使用这个新类。
每项策略都有一个 Exploration 对象,该对象由 AlgorithmConfig 的 .env_runners(exploration_config=...) 方法创建,该方法通过特殊的“type”键指定要使用的类,并通过所有其他键指定构造函数参数,例如:
from ray.rllib.algorithms.algorithm_config import AlgorithmConfig
config = AlgorithmConfig().env_runners(
exploration_config={
# Special `type` key provides class information
"type": "StochasticSampling",
# Add any needed constructor args here.
"constructor_arg": "value",
}
)
下表列出了所有内置的 Exploration 子类及其当前默认使用的代理:

一个 Exploration 类实现了 get_exploration_action 方法,其中定义了确切的探索行为。它接受模型的输出、动作分布类、模型本身、一个时间步(已经完成的全局环境采样步骤)和一个 explore 开关,并输出一个包含 a) 动作和 b) 对数似然的元组。
def get_exploration_action(self,
*,
action_distribution: ActionDistribution,
timestep: Union[TensorType, int],
explore: bool = True):
"""Returns a (possibly) exploratory action and its log-likelihood.
Given the Model's logits outputs and action distribution, returns an
exploratory action.
Args:
action_distribution: The instantiated
ActionDistribution object to work with when creating
exploration actions.
timestep: The current sampling time step. It can be a tensor
for TF graph mode, otherwise an integer.
explore: True: "Normal" exploration behavior.
False: Suppress all exploratory behavior and return
a deterministic action.
Returns:
A tuple consisting of 1) the chosen exploration action or a
tf-op to fetch the exploration action from the graph and
2) the log-likelihood of the exploration action.
"""
pass
在最高层级,Algorithm.compute_actions 和 Policy.compute_actions 方法有一个布尔型的 explore 开关,该开关被传递到 Exploration.get_exploration_action 中。如果 explore=None,则使用 Algorithm.config[“explore”] 的值,因此这作为探索行为的主要开关,例如可以轻松地关闭任何探索以进行评估(参见 训练期间的定制化评估)。
以下是从不同算法的配置(参见 rllib/algorithms/algorithm.py)中提取的示例片段,用于设置不同的探索行为:
# All of the following configs go into Algorithm.config.
# 1) Switching *off* exploration by default.
# Behavior: Calling `compute_action(s)` without explicitly setting its `explore`
# param will result in no exploration.
# However, explicitly calling `compute_action(s)` with `explore=True` will
# still(!) result in exploration (per-call overrides default).
"explore": False,
# 2) Switching *on* exploration by default.
# Behavior: Calling `compute_action(s)` without explicitly setting its
# explore param will result in exploration.
# However, explicitly calling `compute_action(s)` with `explore=False`
# will result in no(!) exploration (per-call overrides default).
"explore": True,
# 3) Example exploration_config usages:
# a) DQN: see rllib/algorithms/dqn/dqn.py
"explore": True,
"exploration_config": {
# Exploration sub-class by name or full path to module+class
# (e.g. “ray.rllib.utils.exploration.epsilon_greedy.EpsilonGreedy”)
"type": "EpsilonGreedy",
# Parameters for the Exploration class' constructor:
"initial_epsilon": 1.0,
"final_epsilon": 0.02,
"epsilon_timesteps": 10000, # Timesteps over which to anneal epsilon.
},
# b) DQN Soft-Q: In order to switch to Soft-Q exploration, do instead:
"explore": True,
"exploration_config": {
"type": "SoftQ",
# Parameters for the Exploration class' constructor:
"temperature": 1.0,
},
# c) All policy-gradient algos and SAC: see rllib/algorithms/algorithm.py
# Behavior: The algo samples stochastically from the
# model-parameterized distribution. This is the global Algorithm default
# setting defined in algorithm.py and used by all PG-type algos (plus SAC).
"explore": True,
"exploration_config": {
"type": "StochasticSampling",
"random_timesteps": 0, # timesteps at beginning, over which to act uniformly randomly
},
训练期间的定制化评估#
RLlib 报告在线训练奖励,但在某些情况下,您可能希望使用不同的设置计算奖励(例如,关闭探索,或在特定的环境配置集上)。您可以通过将 evaluation_interval 设置为一个大于 0 的整数值,来激活在训练期间(Algorithm.train())评估策略,该值表示在每次 Algorithm.train() 调用后应运行一次“评估步骤”。
from ray.rllib.algorithms.algorithm_config import AlgorithmConfig
# Run one evaluation step on every 3rd `Algorithm.train()` call.
config = AlgorithmConfig().evaluation(
evaluation_interval=3,
)
评估步骤运行 - 使用其自身的 EnvRunner 实例 - 持续 evaluation_duration 个回合或时间步,具体取决于 evaluation_duration_unit 设置,该设置可以取值为 "episodes"``(默认)或 ``"timesteps"。
# Every time we run an evaluation step, run it for exactly 10 episodes.
config = AlgorithmConfig().evaluation(
evaluation_duration=10,
evaluation_duration_unit="episodes",
)
# Every time we run an evaluation step, run it for (close to) 200 timesteps.
config = AlgorithmConfig().evaluation(
evaluation_duration=200,
evaluation_duration_unit="timesteps",
)
注意:当使用 evaluation_duration_unit=timesteps 并且你的 evaluation_duration 设置不能被评估工作者的数量(可通过 evaluation_num_env_runners 配置)整除时,RLlib 会将指定的时间步数向上取整到最接近的、能被评估工作者数量整除的整数时间步数。同样,当使用 evaluation_duration_unit=episodes 并且你的 evaluation_duration 设置不能被评估工作者的数量整除时,RLlib 会在前 n 个评估 EnvRunners 上运行剩余的回合,并让剩余的工作者在那段时间内闲置。
例如:
# Every time we run an evaluation step, run it for exactly 10 episodes, no matter,
# how many eval workers we have.
config = AlgorithmConfig().evaluation(
evaluation_duration=10,
evaluation_duration_unit="episodes",
# What if number of eval workers is non-dividable by 10?
# -> Run 7 episodes (1 per eval worker), then run 3 more episodes only using
# evaluation workers 1-3 (evaluation workers 4-7 remain idle during that time).
evaluation_num_env_runners=7,
)
在每次评估步骤之前,主模型的权重会被同步到所有评估工作节点。
默认情况下,评估步骤(如果当前迭代中有)会在相应的训练步骤之后立即运行。例如,对于 evaluation_interval=1,事件序列是:train(0->1), eval(1), train(1->2), eval(2), train(2->3), ...。这里,索引显示了使用的神经网络权重的版本。train(0->1) 是一个更新步骤,将权重从版本 0 更新到版本 1,然后 eval(1) 使用版本 1 的权重。权重索引 0 表示神经网络的随机初始化权重。
另一个例子:对于 evaluation_interval=2,序列是:train(0->1), train(1->2), eval(2), train(2->3), train(3->4), eval(4), ...。
与其按顺序运行 train 和 eval 步骤,还可以通过设置 evaluation_parallel_to_training=True 配置选项来并行运行它们。在这种情况下,训练和评估步骤同时使用多线程运行。这可以显著加快评估过程,但会导致报告的训练和评估结果之间有1次迭代的延迟。在这种情况下,评估结果会滞后,因为它们使用了稍微过时的模型权重(在上一次训练步骤后同步)。
例如,对于 evaluation_parallel_to_training=True 和 evaluation_interval=1,现在的序列是:train(0->1) + eval(0), train(1->2) + eval(1), train(2->3) + eval(2),其中 + 连接同时发生的阶段。注意,相对于非并行示例,权重索引的变化。评估权重索引现在“落后”于训练权重索引(train(1->**2**) + eval(**1**))。
当使用 evaluation_parallel_to_training=True 设置运行时,evaluation_duration 支持一个特殊的“auto”值。这可以用来使评估步骤的时间大致与同时进行的训练步骤相同:
# Run evaluation and training at the same time via threading and make sure they roughly
# take the same time, such that the next `Algorithm.train()` call can execute
# immediately and not have to wait for a still ongoing (e.g. b/c of very long episodes)
# evaluation step:
config = AlgorithmConfig().evaluation(
evaluation_interval=2,
# run evaluation and training in parallel
evaluation_parallel_to_training=True,
# automatically end evaluation when train step has finished
evaluation_duration="auto",
evaluation_duration_unit="timesteps", # <- this setting is ignored; RLlib
# will always run by timesteps (not by complete
# episodes) in this duration=auto mode
)
evaluation_config 键允许你覆盖评估工作者的任何配置设置。例如,要在评估步骤中关闭探索,请执行以下操作:
# Switching off exploration behavior for evaluation workers
# (see rllib/algorithms/algorithm.py). Use any keys in this sub-dict that are
# also supported in the main Algorithm config.
config = AlgorithmConfig().evaluation(
evaluation_config=AlgorithmConfig.overrides(explore=False),
)
# ... which is a more type-checked version of the old-style:
# config = AlgorithmConfig().evaluation(
# evaluation_config={"explore": False},
# )
备注
策略梯度算法能够找到最优策略,即使这是一个随机的策略。设置“explore=False”会导致评估工作线程不使用这个随机策略。
评估步骤中的并行级别由 evaluation_num_env_runners 设置决定。如果你想让所需的评估回合或时间步尽可能并行运行,请将其设置为更大的值。例如,如果你的 evaluation_duration=10,evaluation_duration_unit=episodes,并且 evaluation_num_env_runners=10,每个评估 EnvRunner 在每个评估步骤中只需运行一个回合。
如果在评估期间观察到您的(评估)EnvRunners偶尔失败(例如,您有一个有时会崩溃或停滞的环境),您应使用以下设置组合,以最小化此类环境行为的负面影响:
请注意,无论是否进行并行评估,所有 容错设置,例如 ignore_env_runner_failures 或 recreate_failed_env_runners,都会被尊重并应用于失败的评估工作器。
这是一个例子:
# Having an environment that occasionally blocks completely for e.g. 10min would
# also affect (and block) training. Here is how you can defend your evaluation setup
# against oft-crashing or -stalling envs (or other unstable components on your evaluation
# workers).
config = AlgorithmConfig().evaluation(
evaluation_interval=1,
evaluation_parallel_to_training=True,
evaluation_duration="auto",
evaluation_duration_unit="timesteps", # <- default anyway
evaluation_force_reset_envs_before_iteration=True, # <- default anyway
)
这会并行采样所有评估 EnvRunner,这样即使其中一个 worker 运行一个 episode 并返回数据的时间过长或完全失败,其他评估 EnvRunner 仍然可以完成任务。
如果你想完全自定义评估步骤,请在你的配置中将 custom_eval_function 设置为一个可调用对象,该对象接受一个 Algorithm 对象和一个 EnvRunnerGroup 对象(Algorithm 的 self.evaluation_workers EnvRunnerGroup 实例)并返回一个指标字典。更多文档请参见 algorithm.py。
还有一个端到端的示例,展示了如何设置自定义在线评估,请参见 custom_evaluation.py。请注意,如果您只想在训练结束时评估您的策略,可以设置 evaluation_interval: [int],其中 [int] 应为停止前的训练迭代次数。
以下是一些自定义评估指标如何在正常训练结果的 evaluation 键下嵌套报告的示例:
------------------------------------------------------------------------
Sample output for `python custom_evaluation.py --no-custom-eval`
------------------------------------------------------------------------
INFO algorithm.py:623 -- Evaluating current policy for 10 episodes.
INFO algorithm.py:650 -- Running round 0 of parallel evaluation (2/10 episodes)
INFO algorithm.py:650 -- Running round 1 of parallel evaluation (4/10 episodes)
INFO algorithm.py:650 -- Running round 2 of parallel evaluation (6/10 episodes)
INFO algorithm.py:650 -- Running round 3 of parallel evaluation (8/10 episodes)
INFO algorithm.py:650 -- Running round 4 of parallel evaluation (10/10 episodes)
Result for PG_SimpleCorridor_2c6b27dc:
...
evaluation:
env_runners:
custom_metrics: {}
episode_len_mean: 15.864661654135338
episode_return_max: 1.0
episode_return_mean: 0.49624060150375937
episode_return_min: 0.0
episodes_this_iter: 133
------------------------------------------------------------------------
Sample output for `python custom_evaluation.py`
------------------------------------------------------------------------
INFO algorithm.py:631 -- Running custom eval function <function ...>
Update corridor length to 4
Update corridor length to 7
Custom evaluation round 1
Custom evaluation round 2
Custom evaluation round 3
Custom evaluation round 4
Result for PG_SimpleCorridor_0de4e686:
...
evaluation:
env_runners:
custom_metrics: {}
episode_len_mean: 9.15695067264574
episode_return_max: 1.0
episode_return_mean: 0.9596412556053812
episode_return_min: 0.0
episodes_this_iter: 223
foo: 1
重写轨迹#
请注意,在 on_postprocess_traj 回调中,您可以完全访问轨迹批次 (post_batch) 和其他训练状态。这可以用于重写轨迹,具有多种用途,包括:
将奖励回溯到先前的时间步(例如,基于
info中的值)。在奖励中添加基于模型的探索奖励(你可以使用 自定义模型监督损失 来训练模型)。
要在回调中访问策略/模型 (policy.model),请注意 info['pre_batch'] 返回一个元组,其中第一个元素是策略,第二个元素是批次本身。您还可以使用以下调用来访问所有回滚工作程序状态:
from ray.rllib.evaluation.rollout_worker import get_global_worker
# You can use this from any callback to get a reference to the
# RolloutWorker running in the process, which in turn has references to
# all the policies, etc: see rollout_worker.py for more info.
rollout_worker = get_global_worker()
策略损失是基于 post_batch 数据的定义,因此你可以在回调中对其进行修改,以改变策略损失函数所看到的数据。
