Tune 是如何工作的?#
本页概述了 Tune 的内部工作原理。我们详细描述了当你调用 Tuner.fit() 时会发生什么,Tune 试验的生命周期是怎样的,以及 Tune 的架构组件有哪些。
小技巧
在继续之前,请确保已阅读 Tune 关键概念页面。
Tuner.fit 中发生了什么?#
当调用以下内容时:
space = {"x": tune.uniform(0, 1)}
tuner = tune.Tuner(
my_trainable,
param_space=space,
tune_config=tune.TuneConfig(num_samples=10),
)
results = tuner.fit()
提供的 my_trainable 会使用不同的超参数(从 uniform(0, 1) 中采样)并行评估多次。
每个 Tune 运行都包含“驱动进程”和许多“工作进程”。驱动进程是调用 Tuner.fit() 的 Python 进程(在幕后调用 ray.init())。Tune 驱动进程运行在你运行脚本的节点上(调用 Tuner.fit()),而 Ray Tune 可训练的“角色”运行在任何节点上(无论是同一节点还是在工作节点上(仅限分布式 Ray))。
备注
Ray Actors 允许你在Python中并行化一个类的实例。当你实例化一个Ray actor类时,Ray会在同一台机器(或另一个分布式机器,如果运行Ray集群)上的单独进程中启动该类的实例。然后,这个actor可以异步执行方法调用并维护其自己的内部状态。
驱动程序生成并行工作进程(Ray 角色),这些进程负责使用其超参数配置和提供的可训练对象来评估每个试验。
在可训练对象执行期间(在 Tune 中执行一个可训练对象),Tune 驱动程序通过与每个参与者通信的参与者方法接收中间训练结果并暂停/停止参与者(参见 Tune 试验的生命周期)。
当可训练对象终止(或被停止)时,执行者也会终止。
在 Tune 中执行一个可训练对象#
Tune 使用 Ray 角色 来并行评估多个超参数配置。每个角色都是一个执行用户提供的可训练实例的 Python 进程。
用户提供的 Trainable 的定义将 通过 cloudpickle 序列化) 并发送到每个 actor 进程。每个 Ray actor 将启动一个 Trainable 实例以供执行。
如果可训练对象是一个类,它将通过调用 train/step 进行迭代执行。每次调用后,驱动程序会收到一个“结果字典”已准备好的通知。然后,驱动程序将通过 ray.get 拉取结果。
如果可训练对象是一个可调用对象或函数,它将在 Ray 演员进程中的一个单独执行线程上执行。每当调用 session.report 时,执行线程会暂停并等待驱动程序拉取结果(参见 function_trainable.py)。拉取后,演员的执行线程将自动恢复。
Tune 中的资源管理#
在运行试验之前,Ray Tune 驱动程序将检查集群上是否有可用资源(参见 资源要求)。它会将可用资源与试验所需的资源进行比较。
如果集群上有空间,那么 Tune 驱动程序将启动一个 Ray 角色(工作者)。这个角色将被调度并在某些资源可用的节点上执行。更多信息请参见 Ray Tune 的并行性和资源指南。
Tune 试验的生命周期#
试验的生命周期包含6个阶段:
初始化 (生成): 一个试验首先作为一个超参数样本生成,并根据
Tuner中提供的内容配置其参数。然后,试验被放入队列中等待执行(状态为 PENDING)。待定: 待定试验是指将在机器上执行的试验。每个试验都配置了资源值。每当试验的资源值可用时,Tune 将运行该试验(通过启动一个持有配置和训练函数的 ray 演员)。
运行中: 一个运行中的试验被分配了一个 Ray 角色。可以有多个试验并行运行。更多详情请参见 可训练执行 部分。
错误:如果一个正在运行的试验抛出异常,Tune 将捕获该异常并将试验标记为错误。请注意,异常可以从一个参与者传播到主 Tune 驱动进程。如果设置了 max_retries,Tune 会将试验重新设置为“PENDING”,并在稍后从最后一个检查点开始。
终止: 如果试验被 Stopper/Scheduler 停止,则试验终止。如果使用 Function API,当函数停止时,试验也会终止。
暂停:试验可以由试验调度器暂停。这意味着试验的执行者将被停止。暂停的试验可以从最近的检查点恢复。
Tune 的架构#
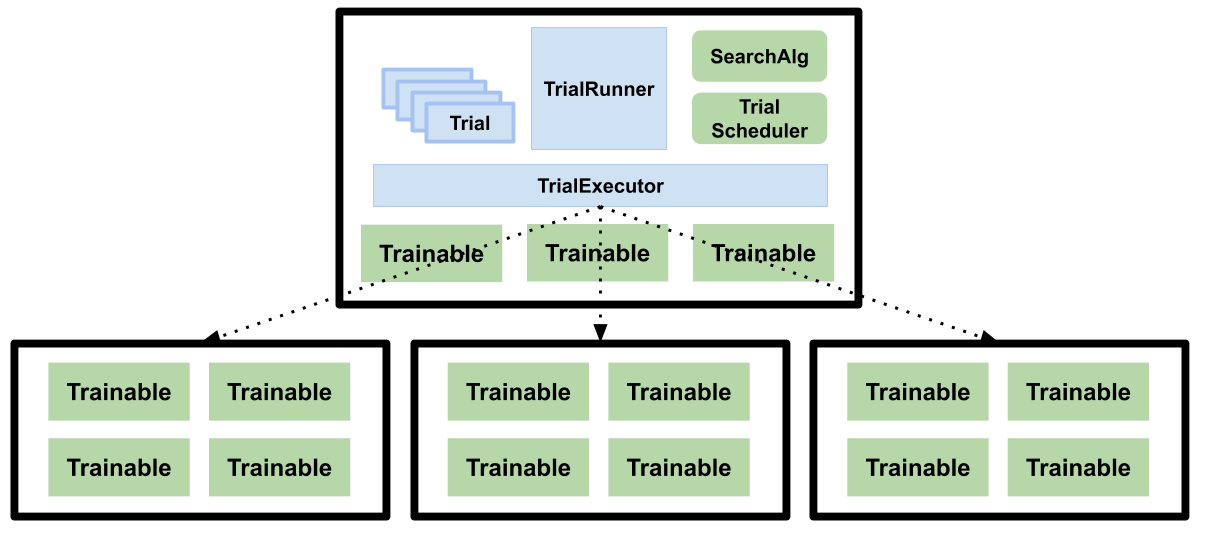
蓝色框表示内部组件,而绿色框表示面向公众的组件。
Tune 的主要组件包括 TuneController、Trial 对象、一个 SearchAlgorithm、一个 TrialScheduler 和一个 Trainable。
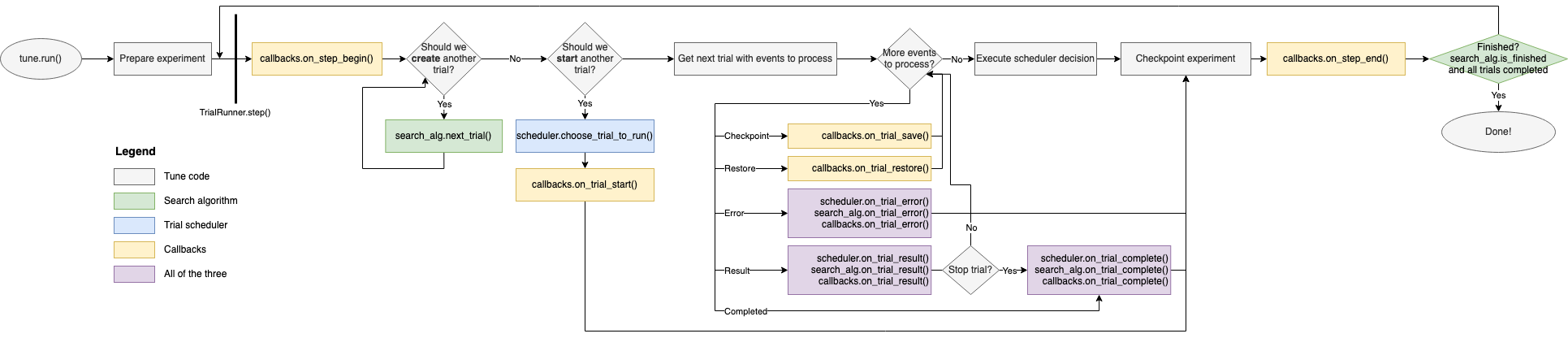
这是一个高级训练流程的示意图,展示了部分组件如何交互:
注意:此图可以水平滚动
TuneController#
[源代码] 这是训练循环的主要驱动程序。该组件使用 TrialScheduler 来优先处理和执行试验,向 SearchAlgorithm 查询新的配置以进行评估,并处理容错逻辑。
容错性:如果设置了 checkpoint_freq,TuneController 会执行检查点操作,并在试验失败时自动重启试验(如果设置了 max_failures)。例如,如果一个节点在试验(具体来说是试验对应的 Trainable)仍在该节点上执行时丢失,并且启用了检查点功能,那么该试验将被恢复到 "PENDING" 状态,并在运行时从最后一个可用的检查点恢复。TuneController 还负责在每次循环迭代时检查点整个实验执行状态。这允许用户在机器故障时重启他们的实验。
请参阅 TuneController 的文档字符串。
试用对象#
[源代码] 这是一个包含每个训练运行元数据的内置数据结构。每个 Trial 对象与一个 Trainable 对象一一对应,但它们本身不是分布式的/远程的。Trial 对象在以下状态之间转换:"PENDING"、"RUNNING"、"PAUSED"、"ERRORED" 和 "TERMINATED"。
请参阅 试验 处的文档字符串。
搜索算法#
[源代码] SearchAlgorithm 是一个用户提供的对象,用于查询新的超参数配置以进行评估。
每次试验完成一个训练步骤(train())、每次试验出错以及每次试验完成时,SearchAlgorithms 都会收到通知。
TrialScheduler#
[源代码] TrialSchedulers 操作于一组可能的试验,根据可用的集群资源优先执行试验。
TrialSchedulers 被赋予了杀死或暂停试验的能力,同时也可以对即将到来的试验进行重新排序/优先级排序。
可训练对象#
[源代码] 这些是用户提供的对象,用于训练过程。如果提供了一个类,则期望它符合 Trainable 接口。如果提供了一个函数,它会被包装成一个 Trainable 类,并且该函数本身会在一个单独的线程中执行。
Trainables 将在通知 TrialRunner 之前执行 train() 的一步。