配置持久存储#
Ray Train 运行会产生 报告的指标、检查点 和 其他工件 的历史记录。您可以配置这些内容以保存到持久存储位置。
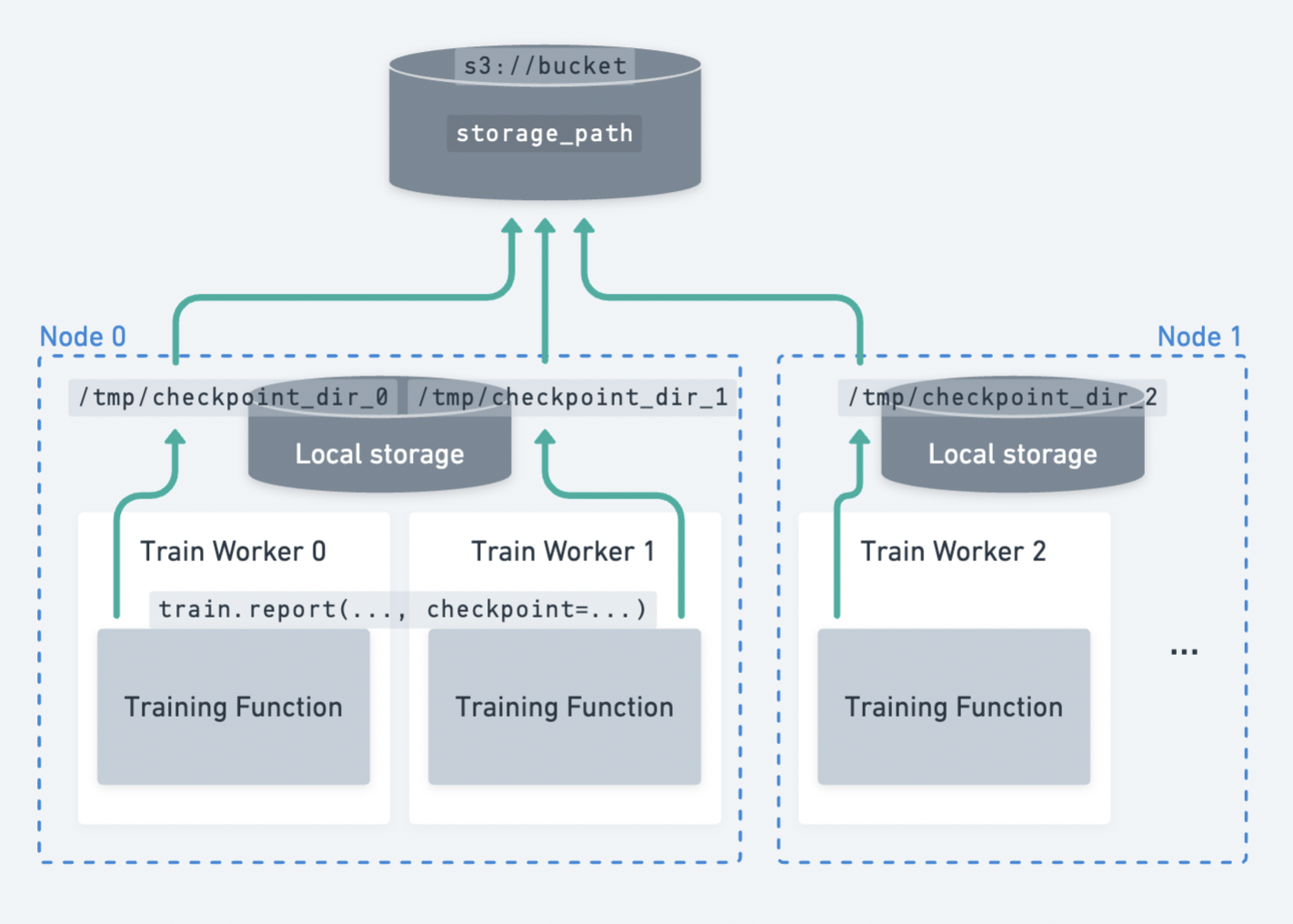
一个在多个节点上分布的多个工作者的示例,它们将检查点上传到持久存储。#
Ray Train 期望所有工作节点都能够写入到同一个持久存储位置。 因此,Ray Train 需要某种形式的外部持久存储,例如云存储(如 S3、GCS)或共享文件系统(如 AWS EFS、Google Filestore、HDFS)用于多节点训练。
以下是持久存储所支持的一些功能:
检查点和容错: 将检查点保存到持久存储位置,可以在节点故障时从最后一个检查点恢复训练。有关如何设置检查点的详细指南,请参阅 保存和加载检查点。
实验后分析: 一个存储所有试验数据的整合位置对于实验后分析非常有用,例如在集群已经终止后访问最佳检查点和超参数配置。
桥接训练/微调与下游服务和批量推理任务:您可以轻松访问模型和工件,以便与他人共享或在下游任务中使用它们。
云存储(AWS S3,Google Cloud Storage)#
小技巧
云存储是推荐的持久存储选项。
通过指定一个桶URI作为 RunConfig(storage_path) 来使用云存储:
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="s3://bucket-name/sub-path/",
name="experiment_name",
)
)
确保Ray集群中的所有节点都能访问云存储,以便工作节点的输出可以上传到共享的云存储桶。在这个例子中,所有文件都被上传到共享存储的 s3://bucket-name/sub-path/experiment_name 以供进一步处理。
本地存储#
为单节点集群使用本地存储#
如果你只是在单个节点上运行实验(例如,在笔记本电脑上),Ray Train 将使用本地文件系统作为检查点和其它工件的存储位置。结果默认保存到 ~/ray_results 中的一个具有唯一自动生成名称的子目录中,除非你使用 RunConfig 中的 storage_path 和 name 进行自定义。
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="/tmp/custom/storage/path",
name="experiment_name",
)
)
在这个例子中,所有实验结果可以在本地 /tmp/custom/storage/path/experiment_name 找到,以便进一步处理。
在多节点集群中使用本地存储#
警告
在多节点运行时,不再支持使用头节点的本地文件系统作为持久存储位置。
如果你使用 ray.train.report(..., checkpoint=...) 保存检查点并在多节点集群上运行,如果未设置 NFS 或云存储,Ray Train 将引发错误。这是因为 Ray Train 期望所有工作节点都能将检查点写入同一个持久存储位置。
如果你的训练循环没有保存检查点,报告的指标仍将被聚合到头节点上的本地存储路径。
更多信息请参见 此问题。
自定义存储#
如果上述情况不符合您的需求,Ray Train 可以支持自定义文件系统并执行自定义逻辑。Ray Train 标准化了 pyarrow.fs.FileSystem 接口以与存储交互(参见 API 参考)。
默认情况下,传递 storage_path=s3://bucket-name/sub-path/ 将使用 pyarrow 的 默认 S3 文件系统实现 来上传文件。(查看其他默认实现。)
通过提供 pyarrow.fs.FileSystem 的实现来实现自定义存储上传和下载逻辑,以用于 RunConfig(storage_filesystem)。
警告
当提供自定义文件系统时,相关的 storage_path 应为一个合格的文件系统路径 不带协议前缀。
例如,如果您为 s3://bucket-name/sub-path/ 提供了一个自定义的 S3 文件系统,那么 storage_path 应该是 bucket-name/sub-path/,去掉 s3://。请参见下面的示例以了解用法。
import pyarrow.fs
from ray import train
from ray.train.torch import TorchTrainer
fs = pyarrow.fs.S3FileSystem(
endpoint_override="http://localhost:9000",
access_key=...,
secret_key=...
)
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_filesystem=fs,
storage_path="bucket-name/sub-path",
name="experiment_name",
)
)
fsspec 文件系统#
fsspec 提供了许多文件系统实现,例如 s3fs、gcsfs 等。
你可以通过将 fsspec 文件系统与 pyarrow.fs 实用工具包装在一起来使用这些实现中的任何一个:
# Make sure to install: `pip install -U s3fs`
import s3fs
import pyarrow.fs
s3_fs = s3fs.S3FileSystem(
key='miniokey...',
secret='asecretkey...',
endpoint_url='https://...'
)
custom_fs = pyarrow.fs.PyFileSystem(pyarrow.fs.FSSpecHandler(s3_fs))
run_config = RunConfig(storage_path="minio_bucket", storage_filesystem=custom_fs)
MinIO 和其他 S3 兼容存储#
您可以按照 上述示例 来配置一个自定义的 S3 文件系统以与 MinIO 一起工作。
请注意,将这些作为查询参数直接包含在 storage_path URI 中是另一种选择:
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="s3://bucket-name/sub-path?endpoint_override=http://localhost:9000",
name="experiment_name",
)
)
Ray Train 输出概述#
到目前为止,我们已经介绍了如何配置 Ray Train 输出的存储位置。让我们通过一个具体的例子来看看这些输出到底是什么,以及它们在存储中是如何结构的。
参见
这个例子包括了检查点功能,这在 保存和加载检查点 中有详细介绍。
import os
import tempfile
from ray import train
from ray.train import Checkpoint
from ray.train.torch import TorchTrainer
def train_fn(config):
for i in range(10):
# Training logic here
metrics = {"loss": ...}
# Save arbitrary artifacts to the working directory
rank = train.get_context().get_world_rank()
with open(f"artifact-rank={rank}-iter={i}.txt", "w") as f:
f.write("data")
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(..., os.path.join(temp_checkpoint_dir, "checkpoint.pt"))
train.report(
metrics,
checkpoint=Checkpoint.from_directory(temp_checkpoint_dir)
)
trainer = TorchTrainer(
train_fn,
scaling_config=train.ScalingConfig(num_workers=2),
run_config=train.RunConfig(
storage_path="s3://bucket-name/sub-path/",
name="experiment_name",
sync_config=train.SyncConfig(sync_artifacts=True),
)
)
result: train.Result = trainer.fit()
last_checkpoint: Checkpoint = result.checkpoint
以下是所有将持久化到存储的文件概述:
s3://bucket-name/sub-path (RunConfig.storage_path)
└── experiment_name (RunConfig.name) <- The "experiment directory"
├── experiment_state-*.json
├── basic-variant-state-*.json
├── trainer.pkl
├── tuner.pkl
└── TorchTrainer_46367_00000_0_... <- The "trial directory"
├── events.out.tfevents... <- Tensorboard logs of reported metrics
├── result.json <- JSON log file of reported metrics
├── checkpoint_000000/ <- Checkpoints
├── checkpoint_000001/
├── ...
├── artifact-rank=0-iter=0.txt <- Worker artifacts (see the next section)
├── artifact-rank=1-iter=0.txt
└── ...
通过 trainer.fit 返回的 Result 和 Checkpoint 对象是访问这些文件中数据的简便方法:
result.filesystem, result.path
# S3FileSystem, "bucket-name/sub-path/experiment_name/TorchTrainer_46367_00000_0_..."
result.checkpoint.filesystem, result.checkpoint.path
# S3FileSystem, "bucket-name/sub-path/experiment_name/TorchTrainer_46367_00000_0_.../checkpoint_000009"
持久化训练工件#
在上面的例子中,我们在训练循环中将一些工件保存到了工作者的 当前工作目录 中。如果你在训练一个稳定扩散模型,你可以每隔一段时间保存一些生成的样本图像作为训练工件。
默认情况下,Ray Train 会将每个工作者的当前工作目录更改为运行中的 本地暂存目录 内。这样,所有分布式训练工作者共享相同的工作目录绝对路径。请参阅 下方 了解如何禁用此默认行为,这在您希望训练工作者保留其原始工作目录时非常有用。
如果 RunConfig(SyncConfig(sync_artifacts=True)),那么此目录中保存的所有工件都将持久化到存储中。
工件同步的频率可以通过 SyncConfig 进行配置。请注意,此行为默认是关闭的。
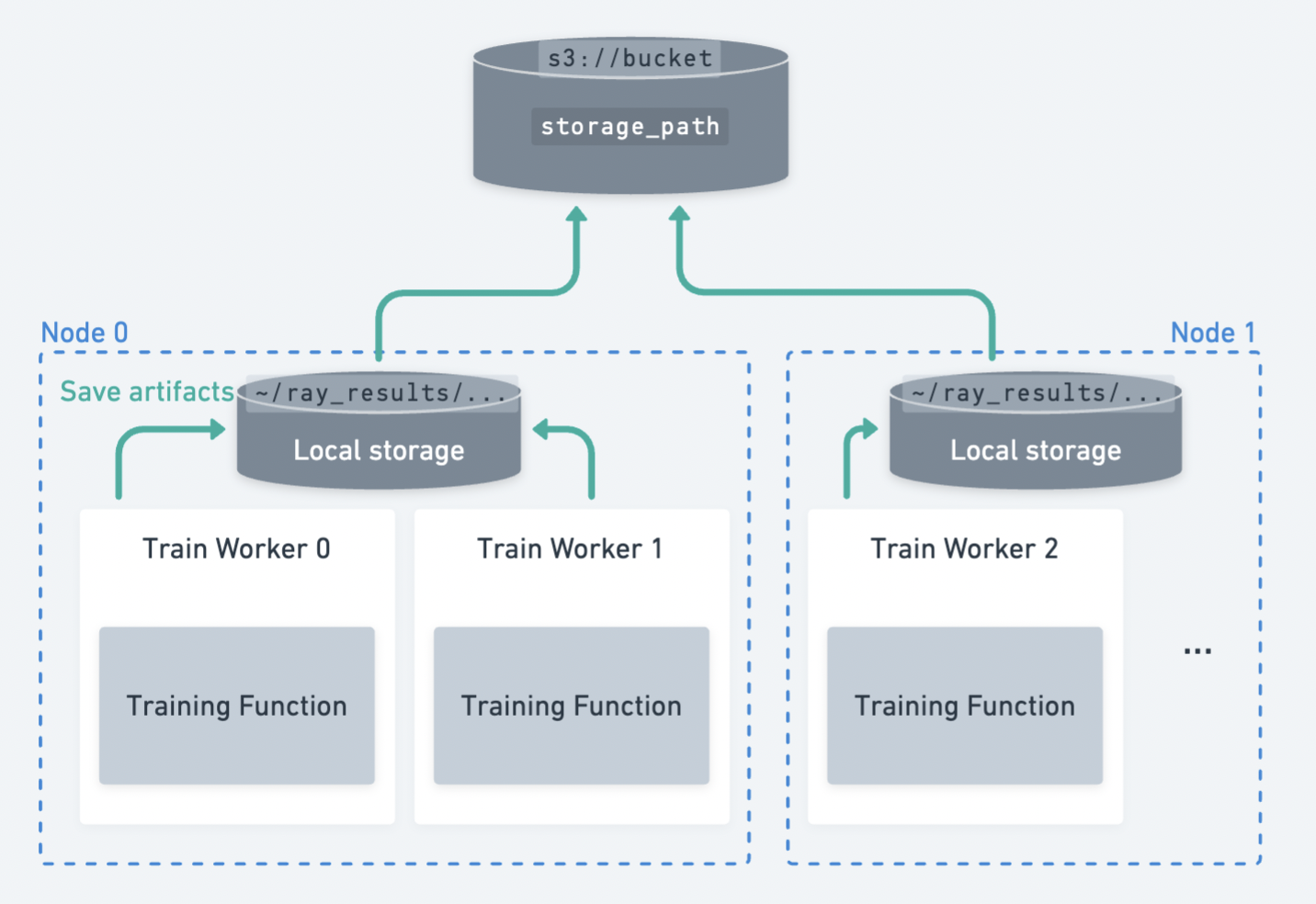
多个工作节点分布在多个节点上,将工件保存到其本地工作目录,然后持久化到存储中。#
警告
由 每个工作节点 保存的工件将被同步到存储中。如果你有多个工作节点位于同一节点上,请确保工作节点不会删除其共享工作目录中的文件。
最佳实践是仅编写来自单个工作者的工件,除非您确实需要来自多个工作者的工件。
from ray import train
if train.get_context().get_world_rank() == 0:
# Only the global rank 0 worker saves artifacts.
...
if train.get_context().get_local_rank() == 0:
# Every local rank 0 worker saves artifacts.
...
高级配置#
设置本地暂存目录#
警告
在2.10版本之前,RAY_AIR_LOCAL_CACHE_DIR 环境变量和 RunConfig(local_dir) 是配置本地暂存目录的方法,使其位于主目录 (~/ray_results) 之外。
这些配置不再用于配置本地暂存目录。请改用 RunConfig(storage_path) 来配置您的运行输出位置。
除了直接写入 storage_path 的检查点文件外,Ray Train 还会在持久化(复制/上传)到 storage_path 之前,将一些日志文件和元数据文件写入一个中间的 本地暂存目录。每个工作者的当前工作目录都设置在这个本地暂存目录内。
默认情况下,本地暂存目录是 Ray 会话目录的子目录(例如,/tmp/ray/session_latest),这也是其他临时 Ray 文件存放的地方。
通过 设置临时 Ray 会话目录的位置 来自定义暂存目录的位置。
以下是本地暂存目录的示例:
/tmp/ray/session_latest/artifacts/<ray-train-job-timestamp>/
└── experiment_name
├── driver_artifacts <- These are all uploaded to storage periodically
│ ├── Experiment state snapshot files needed for resuming training
│ └── Metrics logfiles
└── working_dirs <- These are uploaded to storage if `SyncConfig(sync_artifacts=True)`
└── Current working directory of training workers, which contains worker artifacts
警告
您不需要查看本地暂存目录。storage_path 应该是您唯一需要交互的路径。
本地暂存目录的结构在Ray Train的未来版本中可能会发生变化——请不要在您的应用程序中依赖这些本地暂存文件。
保持原始当前工作目录#
要禁用 Ray Train 更改当前工作目录的默认行为,请设置 RAY_CHDIR_TO_TRIAL_DIR=0 环境变量。
如果你想让你的训练工作器从你启动训练脚本的目录访问相对路径,这会很有用。
import os
import ray
import ray.train
from ray.train.torch import TorchTrainer
os.environ["RAY_CHDIR_TO_TRIAL_DIR"] = "0"
# Write some file in the current working directory
with open("./data.txt", "w") as f:
f.write("some data")
# Set the working directory in the Ray runtime environment
ray.init(runtime_env={"working_dir": "."})
def train_fn_per_worker(config):
# Check that each worker can access the working directory
# NOTE: The working directory is copied to each worker and is read only.
assert os.path.exists("./data.txt"), os.getcwd()
# To use artifact syncing with `SyncConfig(sync_artifacts=True)`,
# write artifacts here, instead of the current working directory:
ray.train.get_context().get_trial_dir()
trainer = TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(num_workers=2),
run_config=ray.train.RunConfig(
# storage_path=...,
sync_config=ray.train.SyncConfig(sync_artifacts=True),
),
)
trainer.fit()
自动设置持久存储#
你可以通过 RAY_STORAGE 环境变量控制训练结果的存储位置。
例如,如果你设置 RAY_STORAGE="s3://my_bucket/train_results" ,你的结果将自动保存在那里。
如果你手动设置 RunConfig.storage_path,它将优先于这个环境变量。
