入门指南#
备注
Workflows 是一个为 Ray 任务图提供强大持久性的库。如果你是 Ray 的新手,我们建议从 核心演练 开始。
你的第一个工作流程#
让我们从一个简单的工作流DAG开始定义,我们将用于下面的示例。这是一个包含三个节点的DAG(注意使用 .bind(...) 而不是 .remote(...))。在对其采取进一步操作之前,DAG不会被执行:
from typing import List
import ray
# Define Ray remote functions.
@ray.remote
def read_data(num: int):
return [i for i in range(num)]
@ray.remote
def preprocessing(data: List[float]) -> List[float]:
return [d**2 for d in data]
@ray.remote
def aggregate(data: List[float]) -> float:
return sum(data)
# Build the DAG:
# data -> preprocessed_data -> aggregate
data = read_data.bind(10)
preprocessed_data = preprocessing.bind(data)
output = aggregate.bind(preprocessed_data)
我们可以使用 ray.dag.vis_utils.plot(output, "output.jpg") 绘制这个DAG:

接下来,让我们执行我们定义的DAG并检查结果:
# <follow the previous code>
from ray import workflow
# Execute the workflow and print the result.
print(workflow.run(output))
# You can also run the workflow asynchronously and fetch the output via
# 'ray.get'
output_ref = workflow.run_async(output)
print(ray.get(output_ref))
285
285
原始DAG中的每个节点都成为一个工作流任务。你可以将工作流任务视为围绕Ray任务的包装器,它们插入*检查点逻辑*以确保中间结果被持久化。这使得工作流DAG在失败时总是能够从最后一个成功的任务恢复。
设置工作流选项#
你可以像设置普通的 Ray 远程函数一样,直接为工作流任务设置 Ray 选项。要设置特定于工作流的选项,可以使用 workflow.options 作为装饰器或作为 <task>.options 的 kwargs:
import ray
from ray import workflow
@workflow.options(checkpoint=True)
@ray.remote(num_cpus=2, num_gpus=3, max_retries=5)
def read_data(num: int):
return [i for i in range(num)]
read_data_with_options = read_data.options(
num_cpus=1, num_gpus=1, **workflow.options(checkpoint=True))
检索工作流结果#
要检索工作流结果,请在工作流运行时分配 workflow_id:
import ray
from ray import workflow
try:
# Cleanup previous workflows
# An exception will be raised if it doesn't exist.
workflow.delete("add_example")
except workflow.exceptions.WorkflowNotFoundError:
pass
@ray.remote
def add(left: int, right: int) -> int:
return left + right
@ray.remote
def get_val() -> int:
return 10
ret = add.bind(get_val.bind(), 20)
print(workflow.run(ret, workflow_id="add_example"))
30
工作流结果可以通过 workflow.get_output(workflow_id) 获取。如果一个工作流没有被赋予 workflow_id,则会随机生成一个字符串作为 workflow_id。要列出所有工作流ID,请调用 ray.workflow.list_all()。
print(workflow.get_output("add_example"))
# "workflow.get_output_async" is an asynchronous version
30
子任务结果#
我们也可以通过 任务 ID 获取单个工作流任务的结果。任务 ID 可以通过 task_id 给出:
通过
.options(**workflow.options(task_id="task_name"))通过装饰器
@workflow.options(task_id="task_name")
如果任务没有指定 task_id,则步骤的函数名称将被设置为 task_id。如果存在多个具有相同 id 的任务,则会添加一个带有计数器 _n 的后缀。
一旦给出了任务ID,任务的结果将可以通过 workflow.get_output(workflow_id, task_id="task_id") 获取。如果任务在流程完成前尚未执行,则会抛出一个异常。以下是一些示例:
import ray
from ray import workflow
workflow_id = "double"
try:
# cleanup previous workflows
workflow.delete(workflow_id)
except workflow.exceptions.WorkflowNotFoundError:
pass
@ray.remote
def double(v):
return 2 * v
inner_task = double.options(**workflow.options(task_id="inner")).bind(1)
outer_task = double.options(**workflow.options(task_id="outer")).bind(inner_task)
result_ref = workflow.run_async(outer_task, workflow_id="double")
inner = workflow.get_output_async(workflow_id, task_id="inner")
outer = workflow.get_output_async(workflow_id, task_id="outer")
assert ray.get(inner) == 2
assert ray.get(outer) == 4
assert ray.get(result_ref) == 4
错误处理#
工作流提供了两种处理应用程序级异常的方法:(1) 自动重试(如在普通的 Ray 任务中),以及 (2) 捕获和处理异常的能力。
如果给出了
max_retries,则在工作流任务失败时,任务将被重试指定的次数。如果
retry_exceptions为 True,则工作流任务会重试任务崩溃和应用程序级别的错误;如果为False,则工作流任务仅重试任务崩溃。如果
catch_exceptions为 True,函数的返回值将被转换为Tuple[Optional[T], Optional[Exception]]。它可以与max_retries结合使用,在返回结果元组之前重试指定的次数。
max_retries 和 retry_exceptions 也是 Ray 任务选项,因此它们应该在 Ray 远程装饰器内部使用。以下是如何使用它们的示例:
# specify in decorator
@workflow.options(catch_exceptions=True)
@ray.remote(max_retries=5, retry_exceptions=True)
def faulty_function():
pass
# specify in .options()
faulty_function.options(max_retries=3, retry_exceptions=False,
**workflow.options(catch_exceptions=False))
备注
默认情况下,retry_exceptions 为 False,而 max_retries 为 3。
这里是一个例子:
from typing import Tuple
import random
import ray
from ray import workflow
@ray.remote
def faulty_function() -> str:
if random.random() > 0.5:
raise RuntimeError("oops")
return "OK"
# Tries up to five times before giving up.
r1 = faulty_function.options(max_retries=5).bind()
try:
workflow.run(r1)
except ray.exceptions.RayTaskError:
pass
@ray.remote
def handle_errors(result: Tuple[str, Exception]):
# The exception field will be None on success.
err = result[1]
if err:
return "There was an error: {}".format(err)
else:
return "OK"
# `handle_errors` receives a tuple of (result, exception).
r2 = faulty_function.options(**workflow.options(catch_exceptions=True)).bind()
workflow.run(handle_errors.bind(r2))
耐久性保证#
工作流任务提供 恰好一次 执行语义。这意味着 一旦工作流任务的结果被记录到持久存储中,Ray 保证该任务将永远不会被重新执行。接收另一个工作流任务输出的任务可以确保其输入任务永远不会被重新执行。
故障模型#
如果集群失败,任何在集群上运行的工作流将进入
RESUMABLE状态。这些工作流可以在另一个集群上恢复(参见管理API部分)。工作流的生存期与驱动程序无关。如果驱动程序退出,工作流将继续在集群的后台运行。
请注意,具有副作用的任务仍然需要是幂等的。这是因为任务在其结果被记录之前总是可能失败。
非幂等工作流:
@ray.remote
def book_flight_unsafe() -> FlightTicket:
ticket = service.book_flight()
# Uh oh, what if we failed here?
return ticket
# UNSAFE: we could book multiple flight tickets
workflow.run(book_flight_unsafe.bind())
幂等工作流:
@ray.remote
def generate_id() -> str:
# Generate a unique idempotency token.
return uuid.uuid4().hex
@ray.remote
def book_flight_idempotent(request_id: str) -> FlightTicket:
if service.has_ticket(request_id):
# Retrieve the previously created ticket.
return service.get_ticket(request_id)
return service.book_flight(request_id)
# SAFE: book_flight is written to be idempotent
request_id = generate_id.bind()
workflow.run(book_flight_idempotent.bind(request_id))
动态工作流#
Ray DAGs 是静态的 – 从一个节点返回另一个节点不是构建图的有效方式。例如,以下代码打印的是一个 DAG 节点,而不是 bar 的输出:
@ray.remote
def bar():
print("Hello from bar!")
@ray.remote
def foo():
# This is evaluated at runtime, not in DAG construction.
return bar.bind()
# Executing `foo` returns the `bar` DAG node, *not* its result.
print("Output of foo DAG:", type(ray.get(foo.bind().execute())))
Output of foo DAG: <class 'ray.dag.function_node.FunctionNode'>
为了在运行时动态执行DAG节点,工作流引入了一个名为 workflow.continuation 的实用函数:
@ray.remote
def bar():
return 10
@ray.remote
def foo():
# This will return a DAG to be executed
# after this function is finished.
return workflow.continuation(bar.bind())
assert ray.get(foo.bind().execute()) == 10
assert workflow.run(foo.bind()) == 10
动态工作流支持在工作流中嵌套、循环和递归。
以下示例展示了如何使用动态工作流实现递归 factorial 程序:
@ray.remote
def factorial(n: int) -> int:
if n == 1:
return 1
else:
# Here a DAG is passed to the continuation.
# The DAG will continue to be executed after this task.
return workflow.continuation(multiply.bind(n, factorial.bind(n - 1)))
@ray.remote
def multiply(a: int, b: int) -> int:
return a * b
assert workflow.run(factorial.bind(10)) == 3628800
# You can also execute the code with Ray DAG engine.
assert ray.get(factorial.bind(10).execute()) == 3628800
需要注意的关键行为是,当一个任务返回一个由 workflow.continuation 包装的 DAG 而不是具体值时,该包装的 DAG 将被替换为任务的返回值。
为了更好地理解动态工作流程,让我们来看一个更现实的预订旅行的例子:
@ray.remote
def book_flight(...) -> Flight: ...
@ray.remote
def book_hotel(...) -> Hotel: ...
@ray.remote
def finalize_or_cancel(
flights: List[Flight],
hotels: List[Hotel]) -> Receipt: ...
@ray.remote
def book_trip(origin: str, dest: str, dates) -> Receipt:
# Note that the workflow engine will not begin executing
# child workflows until the parent task returns.
# This avoids task overlap and ensures recoverability.
f1 = book_flight.bind(origin, dest, dates[0])
f2 = book_flight.bind(dest, origin, dates[1])
hotel = book_hotel.bind(dest, dates)
return workflow.continuation(finalize_or_cancel.bind([f1, f2], [hotel]))
receipt: Receipt = workflow.run(book_trip.bind("OAK", "SAN", ["6/12", "7/5"]))
这里的工作流程最初只包含 book_trip 任务。一旦执行,book_trip 会生成并行预订航班和酒店的任务,这些任务将进入一个决定是否取消行程或最终确定行程的任务。DAG 可以可视化如下(注意 book_trip 内动态生成的嵌套工作流程):
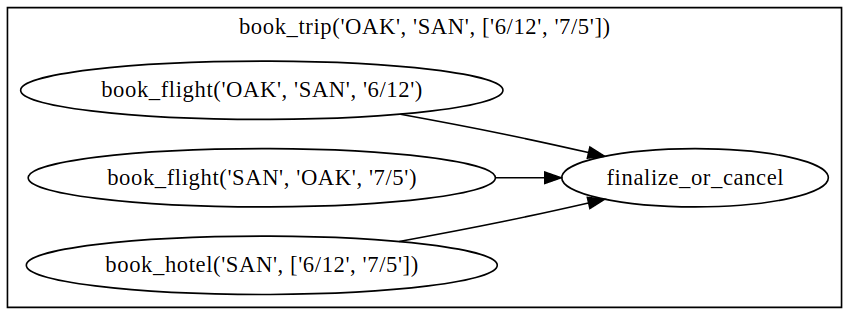
执行顺序如下:1. 运行 book_trip 任务。2. 并行运行两个 book_flight 任务和 book_hotel 任务。3. 一旦所有三个预订任务完成,将执行 finalize_or_cancel ,其返回值将是工作流的输出。
Ray 集成#
将工作流任务与 Ray 任务和角色混合#
工作流与 Ray 任务和角色兼容。有两种方法可以一起使用它们:
工作流可以从 Ray 任务或角色内部启动。例如,您可以从 Ray serve 中启动一个长时间运行的工作流以响应用户请求。这与从驱动程序启动工作流没有什么不同。
工作流任务可以在单个任务中使用 Ray 任务或角色。例如,一个任务可以在内部使用 Ray Train 来训练模型。对于任务中使用的任务或角色,不提供持久性保证;如果任务失败,它将从头开始重新执行。
传递嵌套参数#
与 Ray 任务类似,当你将一个任务输出的列表传递给另一个任务时,这些值并未被解析。但我们确保在任务开始之前,其所有祖先任务都已完全执行完毕,这与将它们传递给 Ray 远程函数不同,无论它们是否已执行,其行为都是未定义的。
@ray.remote
def add(values: List[ray.ObjectRef]) -> int:
# although those values are not resolved, they have been
# *fully executed and checkpointed*. This guarantees exactly-once
# execution semantics.
return sum(ray.get(values))
@ray.remote
def get_val() -> int:
return 10
ret = add.bind([get_val.bind() for _ in range(3)])
assert workflow.run(ret) == 30
在任务之间传递对象引用#
Ray 对象引用及其组成的数据结构(例如 ray.Dataset)可以传递到工作流任务中并从中返回。为了确保可恢复性,它们的内容将在执行前记录到持久存储中。然而,即使对象被传递到许多不同的任务中,它也不会被检查点化超过一次。
@ray.remote
def do_add(a, b):
return a + b
@ray.remote
def add(a, b):
return do_add.remote(a, b)
workflow.run(add.bind(ray.put(10), ray.put(20))) == 30
Ray actor 句柄不允许在任务之间传递。
为任务设置自定义资源#
你可以通过相同的 num_cpus、num_gpus 和 resources 参数为任务分配资源(例如,CPU、GPU),这些参数与 Ray 任务所使用的参数相同。
@ray.remote
def train_model():
pass # This task is assigned to a GPU by Ray.
workflow.run(train_model.options(num_gpus=1).bind())
