在VS Code中开始使用数据整理器
Data Wrangler 是一个以代码为中心的数据查看和清理工具,集成在 VS Code 和 VS Code Jupyter Notebooks 中。它提供了一个丰富的用户界面来查看和分析您的数据,显示有洞察力的列统计信息和可视化,并在您清理和转换数据时自动生成 Pandas 代码。
以下是一个从笔记本中打开Data Wrangler以使用内置操作分析和清理数据的示例。然后,自动生成的代码被导出回笔记本中。
本文档涵盖如何:
- 安装并设置Data Wrangler
- 从笔记本启动数据整理器
- 从数据文件启动数据整理器
- 使用数据整理器探索您的数据
- 使用Data Wrangler对数据进行操作和清理
- 编辑并将数据整理代码导出到笔记本
- 故障排除和提供反馈
设置您的环境
- 如果尚未安装,请安装Python。 重要提示: Data Wrangler 仅支持 Python 3.8 或更高版本。
- 安装 Visual Studio Code。
- 安装 Data Wrangler 扩展
当你第一次启动Data Wrangler时,它会询问你想要连接到哪个Python内核。它还会检查你的机器和环境,看看是否安装了所需的Python包,例如Pandas。
以下是Python和Python包所需的版本列表,以及它们是否由Data Wrangler自动安装:
| Name | Minimum required version | Automatically installed |
|---|---|---|
| Python | 3.8 | No |
| pandas | 0.25.2 | Yes |
如果在您的环境中找不到这些依赖项,Data Wrangler 将尝试使用 pip 为您安装它们。如果 Data Wrangler 无法安装这些依赖项,最简单的解决方法是手动运行 pip install,然后再次启动 Data Wrangler。这些依赖项是 Data Wrangler 所必需的,以便它可以生成 Python 和 Pandas 代码。
开放数据整理工具
每当你在Data Wrangler中时,你都在一个沙盒环境中,这意味着你可以安全地探索和转换数据。原始数据集在你明确导出更改之前不会被修改。
从Jupyter Notebook启动Data Wrangler
有三种方法可以从您的Jupyter Notebook启动Data Wrangler
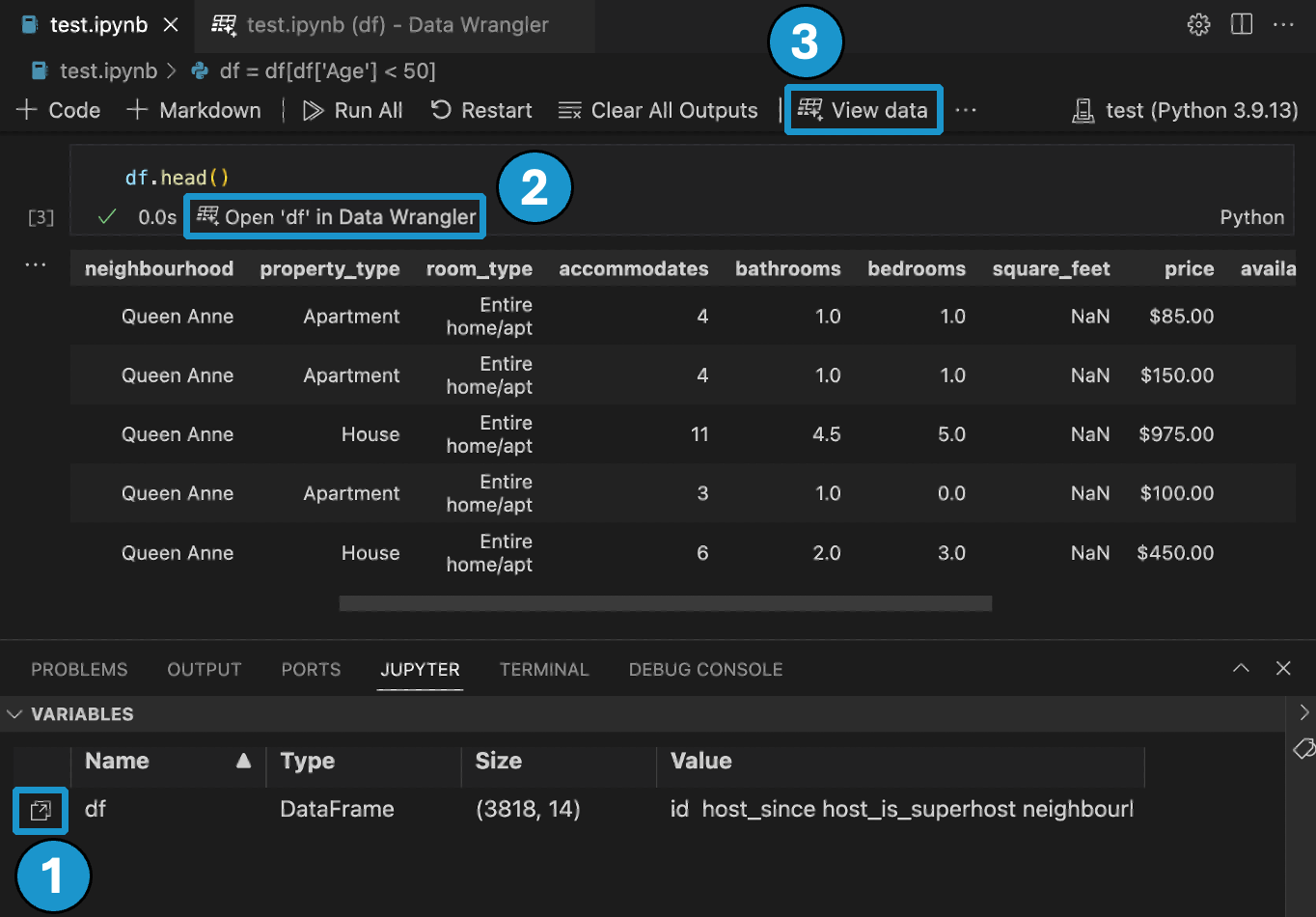
- 在Jupyter > Variables面板中,任何支持的数据对象旁边,您都可以看到一个启动Data Wrangler的按钮。
- 如果您在笔记本中有一个Pandas数据框,现在可以在运行输出数据框的代码后,在单元格底部看到一个在Data Wrangler中打开'df'按钮(其中'df'是您的数据框的变量名称)。这包括1)
df.head(), 2)df.tail(), 3)display(df), 4)print(df), 5)df。 - 在笔记本工具栏中,选择查看数据会显示笔记本中所有支持的数据对象列表。然后您可以选择该列表中的哪个变量要在Data Wrangler中打开。
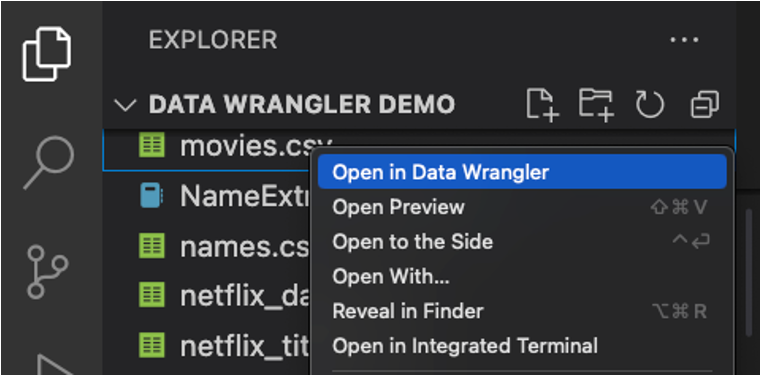
直接从文件启动数据整理器
你也可以直接从本地文件(例如.csv)启动Data Wrangler。为此,在VS Code中打开包含你想要打开的文件的任何文件夹。在文件资源管理器视图中,右键点击文件并点击在Data Wrangler中打开。
数据整理器目前支持以下文件类型
.csv/.tsv.xls/.xlsx.parquet
根据文件类型,您可以指定文件的分隔符和/或工作表。
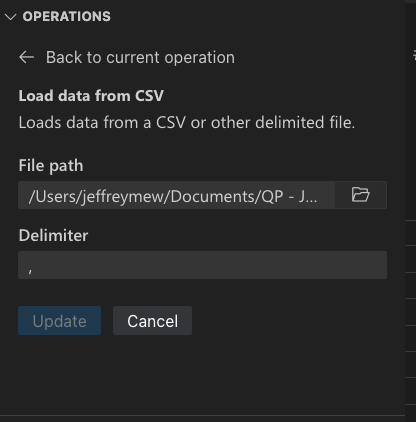
你也可以默认设置这些文件类型用Data Wrangler打开。
用户界面导览
Data Wrangler 在处理数据时有两种模式。每种模式的详细信息将在下面的章节中解释。
- 查看模式: 查看模式优化了界面,使您能够快速查看、过滤和排序数据。此模式非常适合对数据集进行初步探索。
- 编辑模式: 编辑模式优化了界面,以便您对数据集应用转换、清理或修改。当您在界面中应用这些转换时,Data Wrangler 会自动生成相关的 Pandas 代码,并且可以将其导出回您的笔记本以供重复使用。
注意:默认情况下,Data Wrangler 在查看模式下打开。您可以在设置编辑器中更改此行为 。

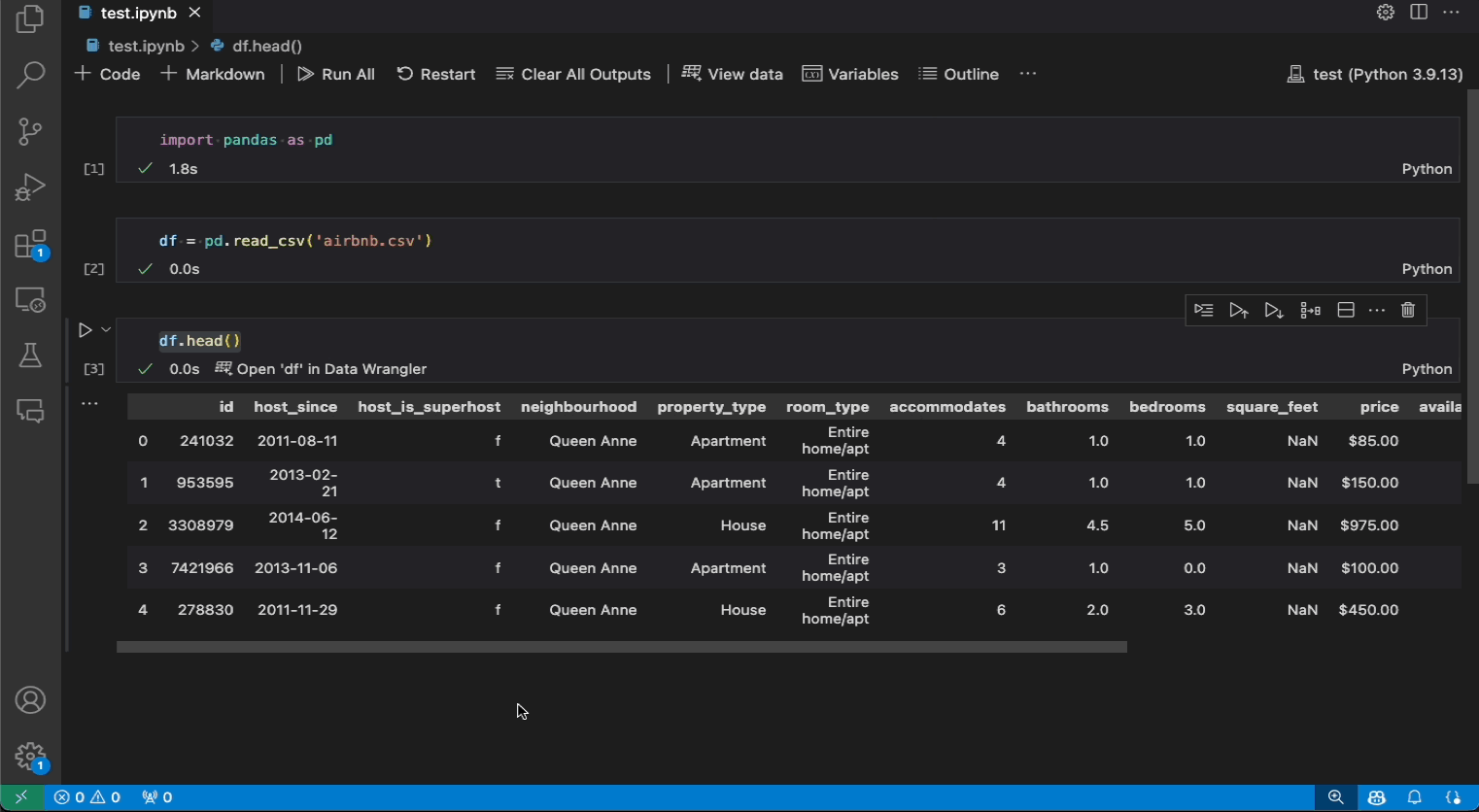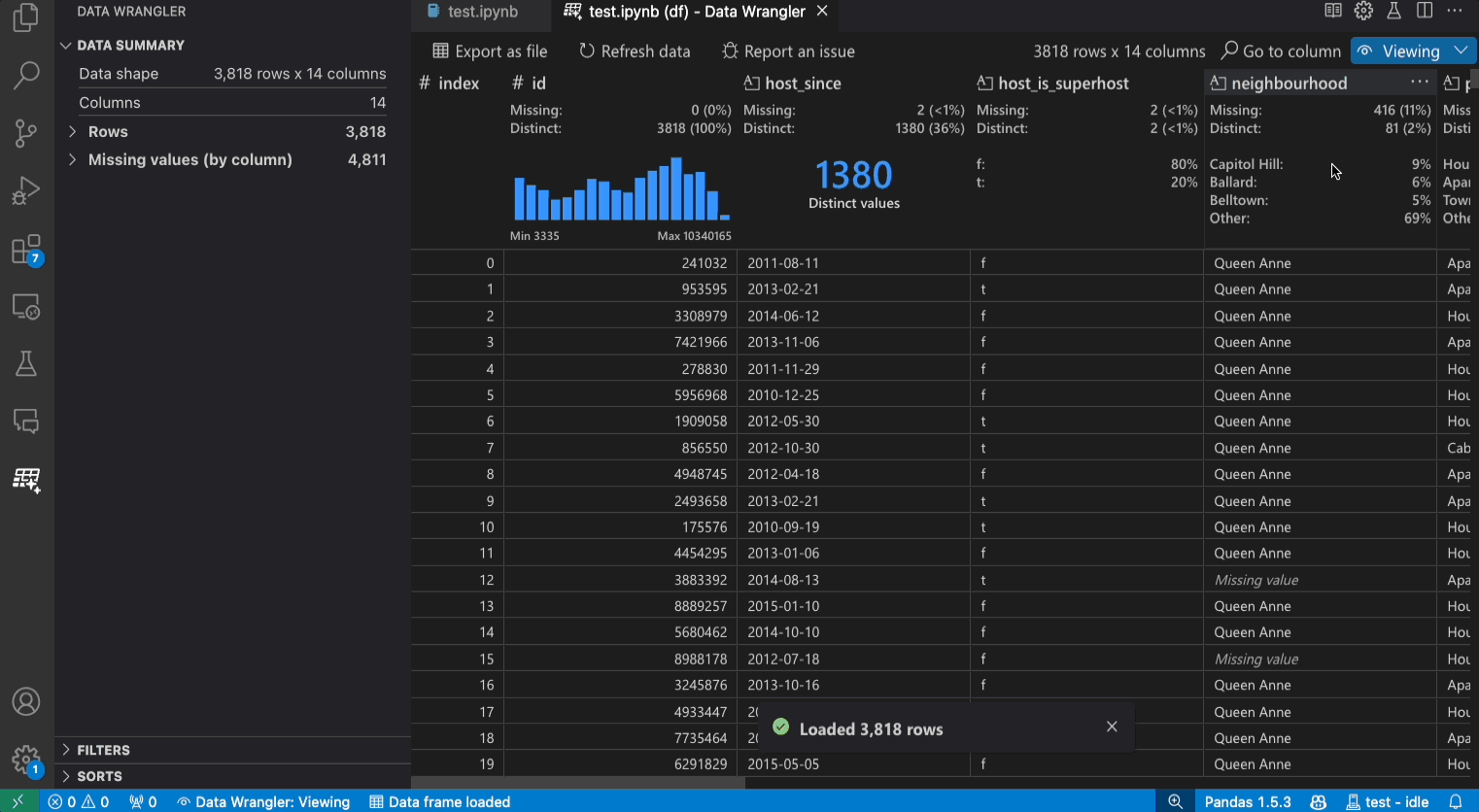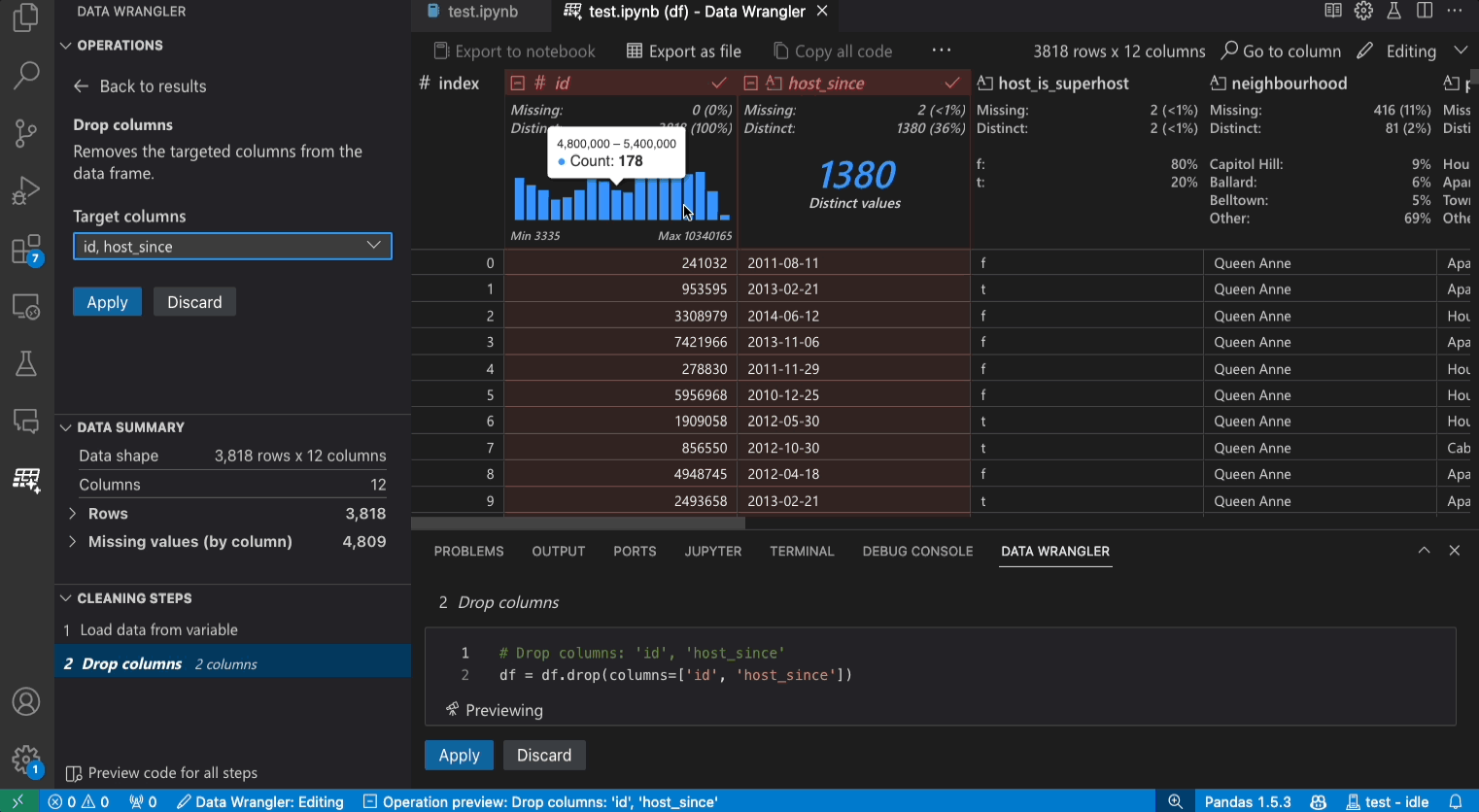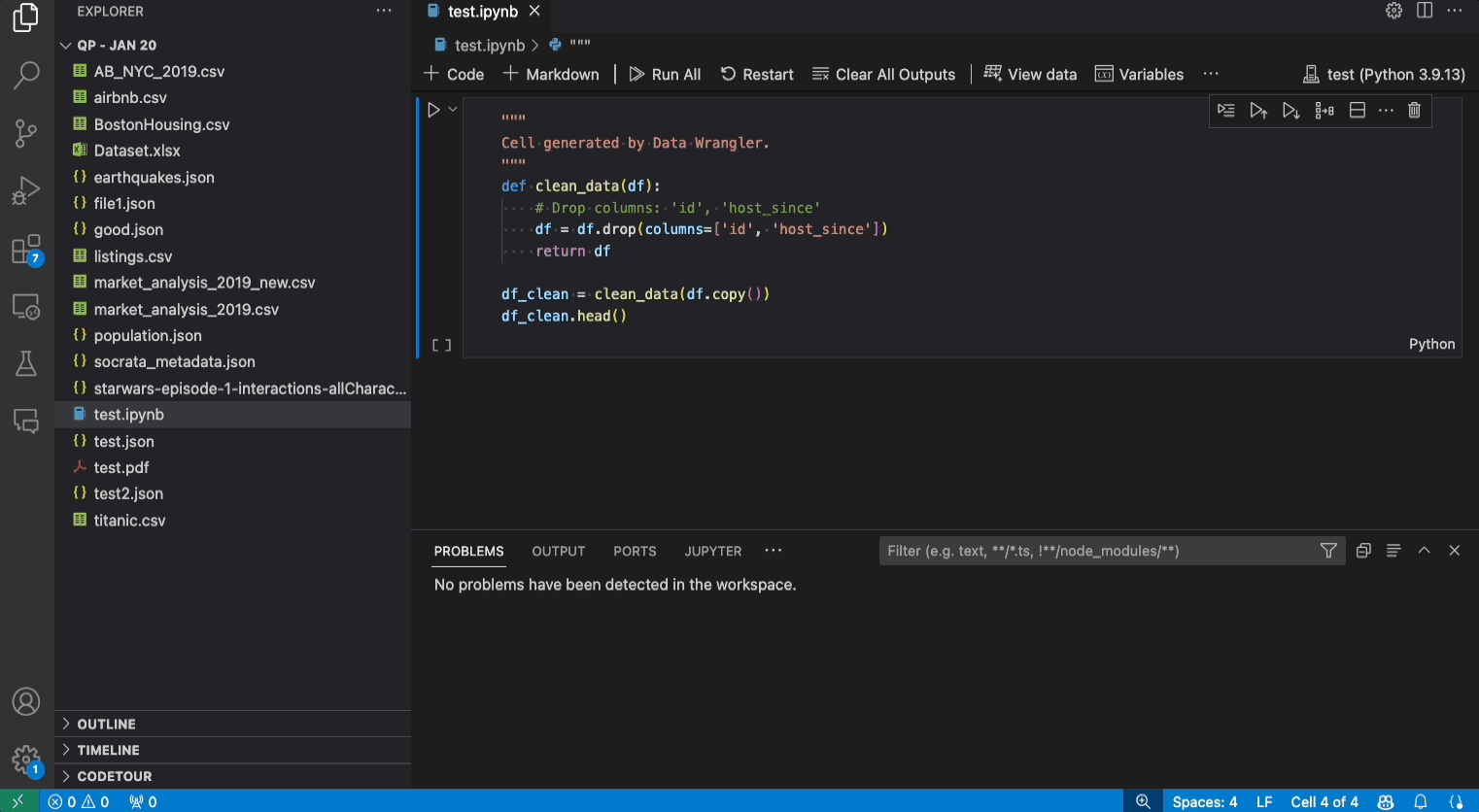
查看模式界面
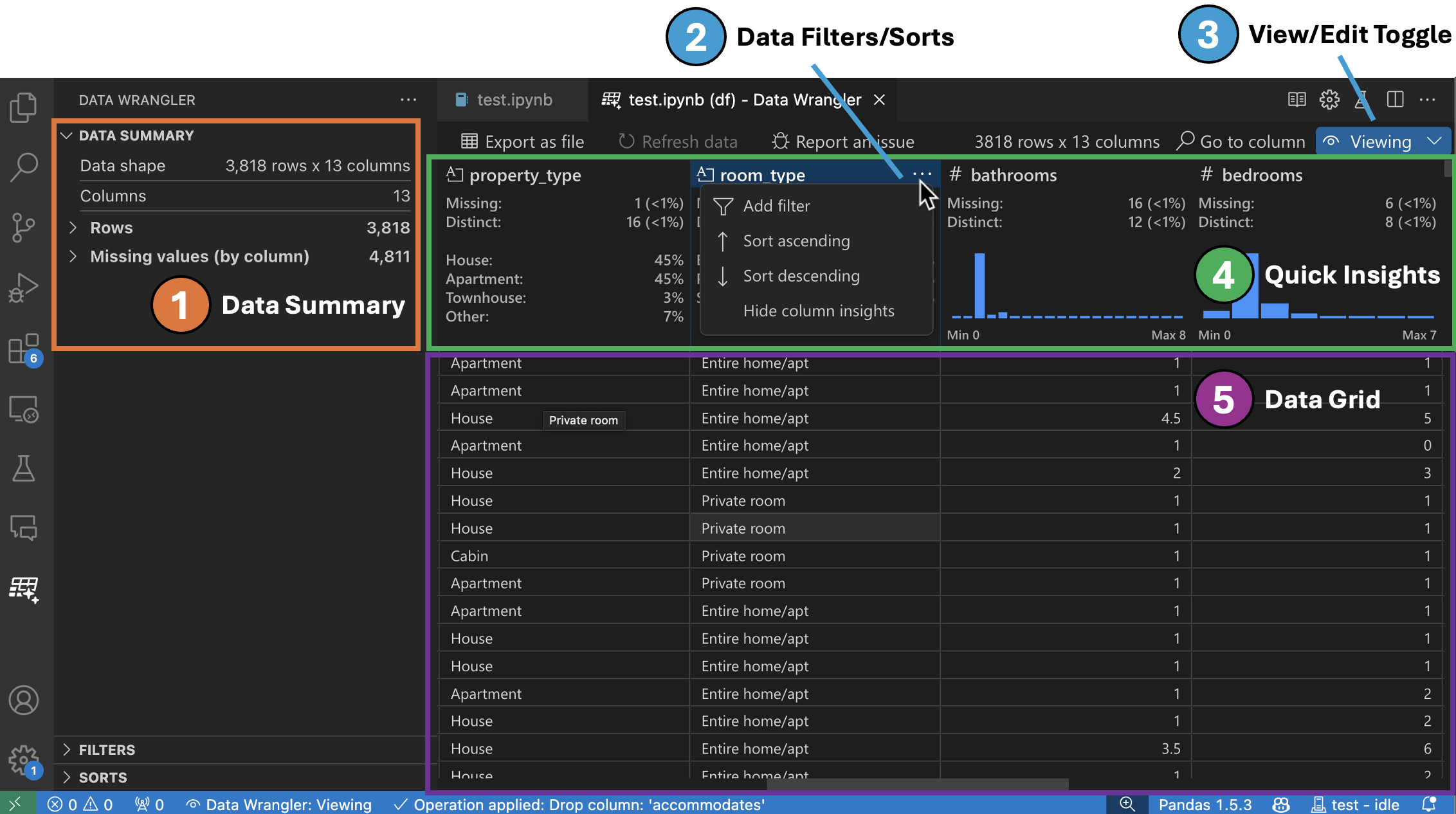
-
数据摘要面板显示您整个数据集或特定列的详细摘要统计信息(如果已选择)。
-
您可以从列的标题菜单中对列应用任何数据过滤器/排序。
-
在Data Wrangler的查看或编辑模式之间切换,以访问内置的数据操作。
-
快速洞察标题是您可以快速查看每列有价值信息的地方。根据列的数据类型,快速洞察显示数据的分布或数据点的频率,以及缺失值和唯一值。
-
数据网格为您提供了一个可滚动的窗格,您可以在其中查看整个数据集。
编辑模式界面
切换到编辑模式可以在数据整理器中启用额外的功能和用户界面元素。在下面的截图中,我们使用数据整理器将最后一列中的缺失值替换为该列的中位数。
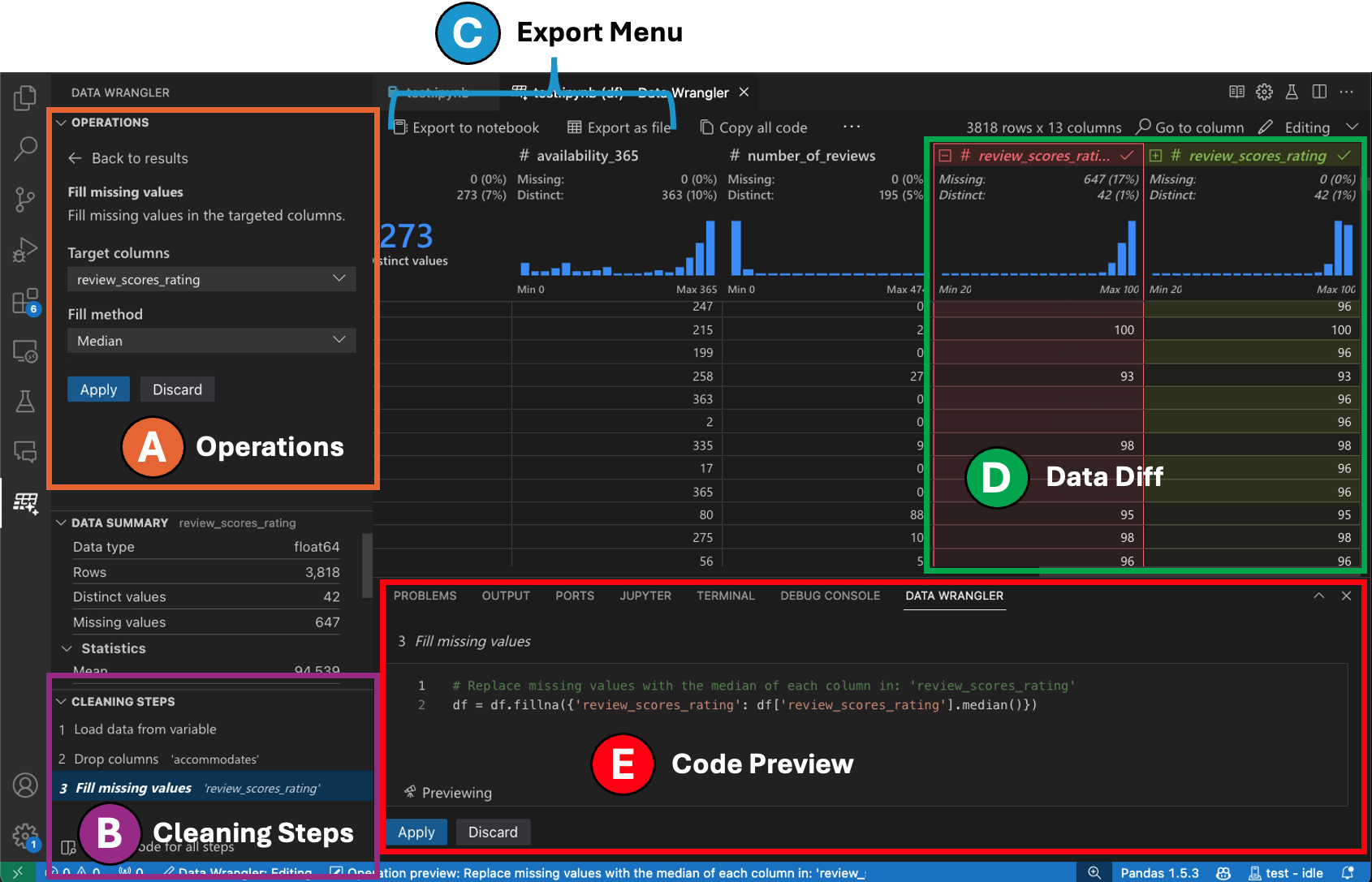
-
操作面板是您可以搜索所有Data Wrangler内置数据操作的地方。这些操作按类别组织。
-
清理步骤面板显示了之前应用的所有操作列表。它使用户能够撤销特定操作或编辑最近的操作。选择一个步骤将在数据差异视图中突出显示更改,并显示与该操作相关的生成代码。
-
导出菜单允许您将代码导出回Jupyter Notebook或将数据导出到新文件中。
-
当您选择了一个操作并预览其对数据的影响时,网格会覆盖一个数据差异视图,显示您对数据所做的更改。
-
代码预览部分显示了当选择操作时,Data Wrangler 生成的 Python 和 Pandas 代码。当没有选择操作时,它保持为空。您可以编辑生成的代码,这将导致数据网格突出显示对数据的影响。
数据整理操作
内置的数据整理操作可以从操作面板中选择。
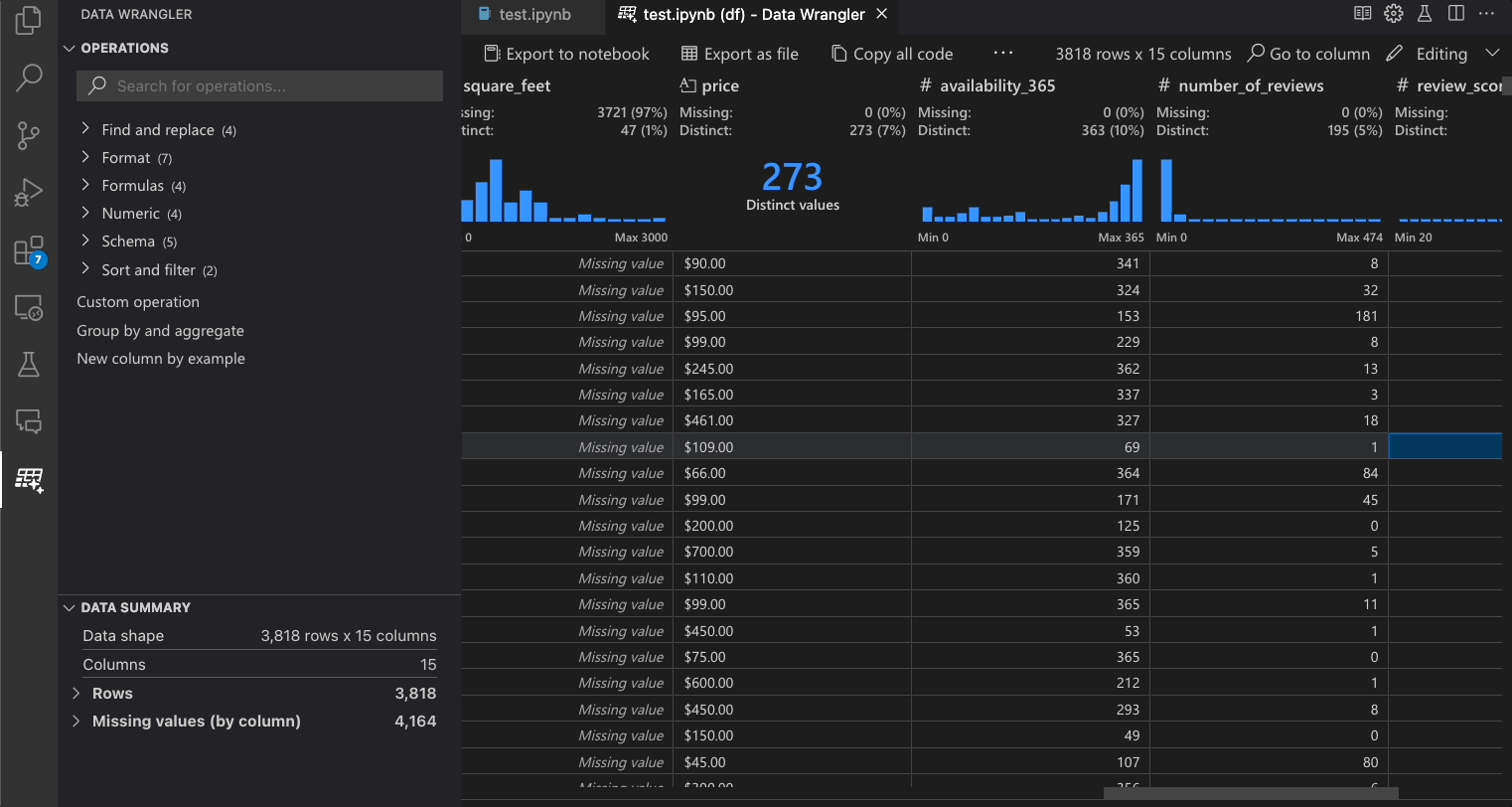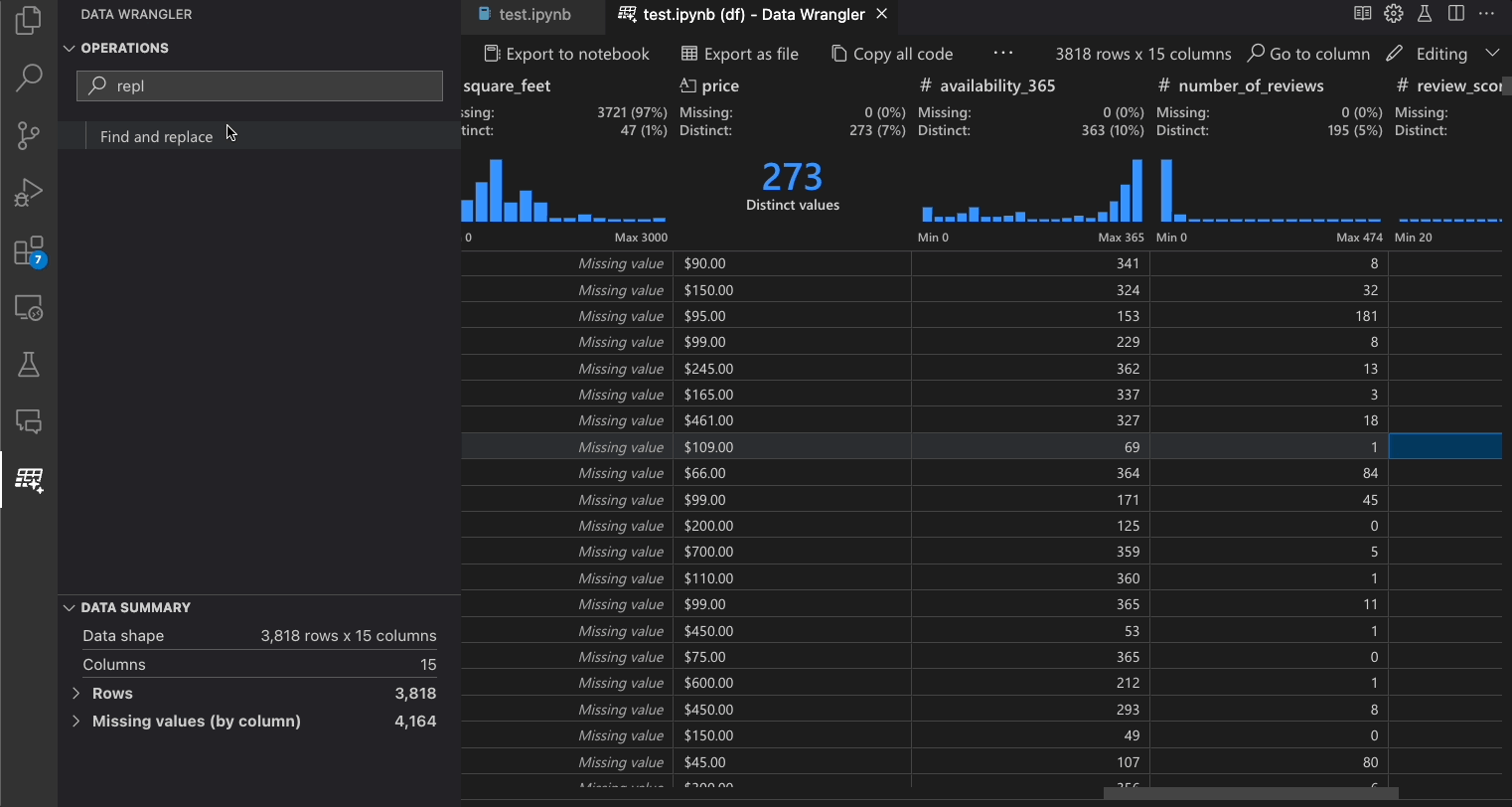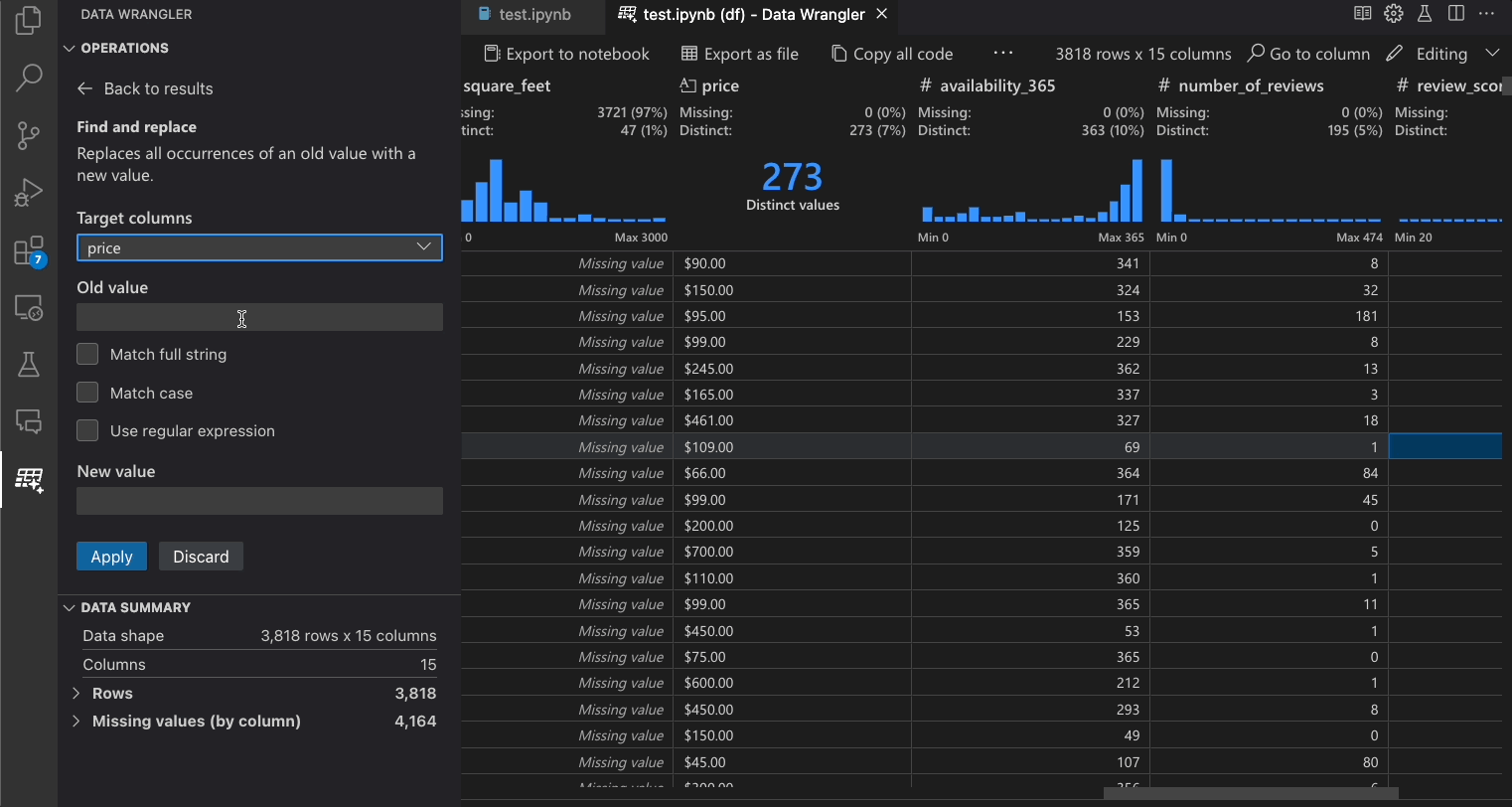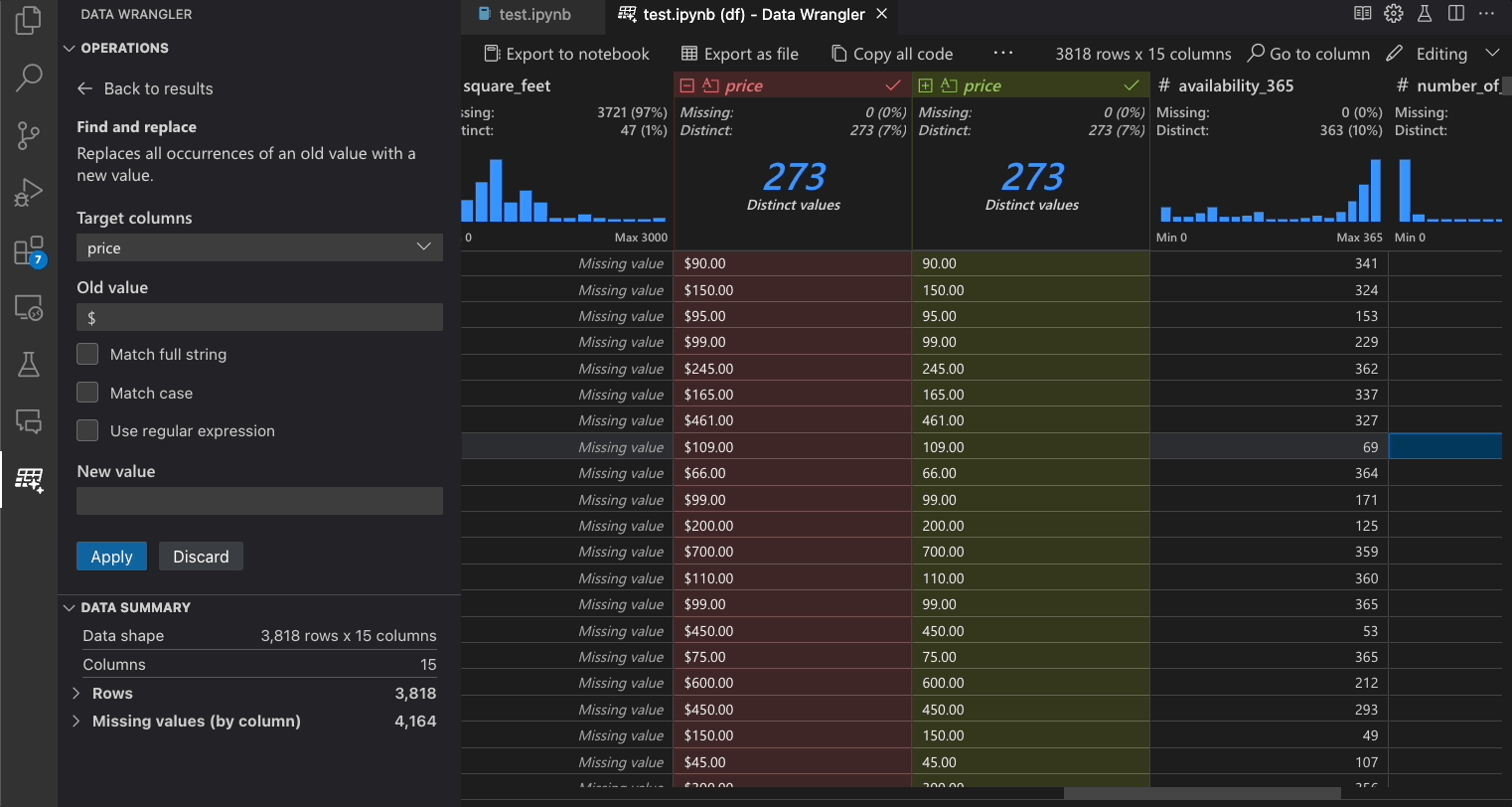
下表列出了在Data Wrangler初始版本中当前支持的数据整理操作。我们计划在不久的将来添加更多操作。
| Operation | Description |
|---|---|
| Sort | Sort column(s) ascending or descending |
| Filter | Filter rows based on one or more conditions |
| Calculate text length | Create new column with values equal to the length of each string value in a text column |
| One-hot encode | Split categorical data into a new column for each category |
| Multi-label binarizer | Split categorical data into a new column for each category using a delimiter |
| Create column from formula | Create a column using a custom Python formula |
| Change column type | Change the data type of a column |
| Drop column | Delete one or more columns |
| Select column | Choose one or more columns to keep and delete the rest |
| Rename column | Rename one or more columns |
| Clone column | Create a copy of one or more columns |
| Drop missing values | Remove rows with missing values |
| Drop duplicate rows | Drops all rows that have duplicate values in one or more columns |
| Fill missing values | Replace cells with missing values with a new value |
| Find and replace | Replace cells with a matching pattern |
| Group by column and aggregate | Group by columns and aggregate results |
| Strip whitespace | Remove whitespace from the beginning and end of text |
| Split text | Split a column into several columns based on a user defined delimiter |
| Capitalize first character | Converts first character to uppercase and remaining to lowercase |
| Convert text to lowercase | Convert text to lowercase |
| Convert text to uppercase | Convert text to UPPERCASE |
| String transform by example | Automatically perform string transformations when a pattern is detected from the examples you provide |
| DateTime formatting by example | Automatically perform DateTime formatting when a pattern is detected from the examples you provide |
| New column by example | Automatically create a column when a pattern is detected from the examples you provide. |
| Scale min/max values | Scale a numerical column between a minimum and maximum value |
| Round | Rounds numbers to the specified number of decimal places |
| Round down (floor) | Rounds numbers down to the nearest integer |
| Round up (ceiling) | Rounds numbers up to the nearest integer |
| Custom operation | Automatically create a new column based on examples and the derivation of existing column(s) |
如果有一个操作缺失并且您希望在Data Wrangler中看到支持,请在我们的Data Wrangler GitHub仓库中提交功能请求。
修改之前的步骤
生成的代码的每一步都可以通过清理步骤面板进行修改。首先,选择您想要修改的步骤。然后,当您对操作进行更改时(无论是通过代码还是操作面板),您的更改对数据的影响将在网格视图中突出显示。
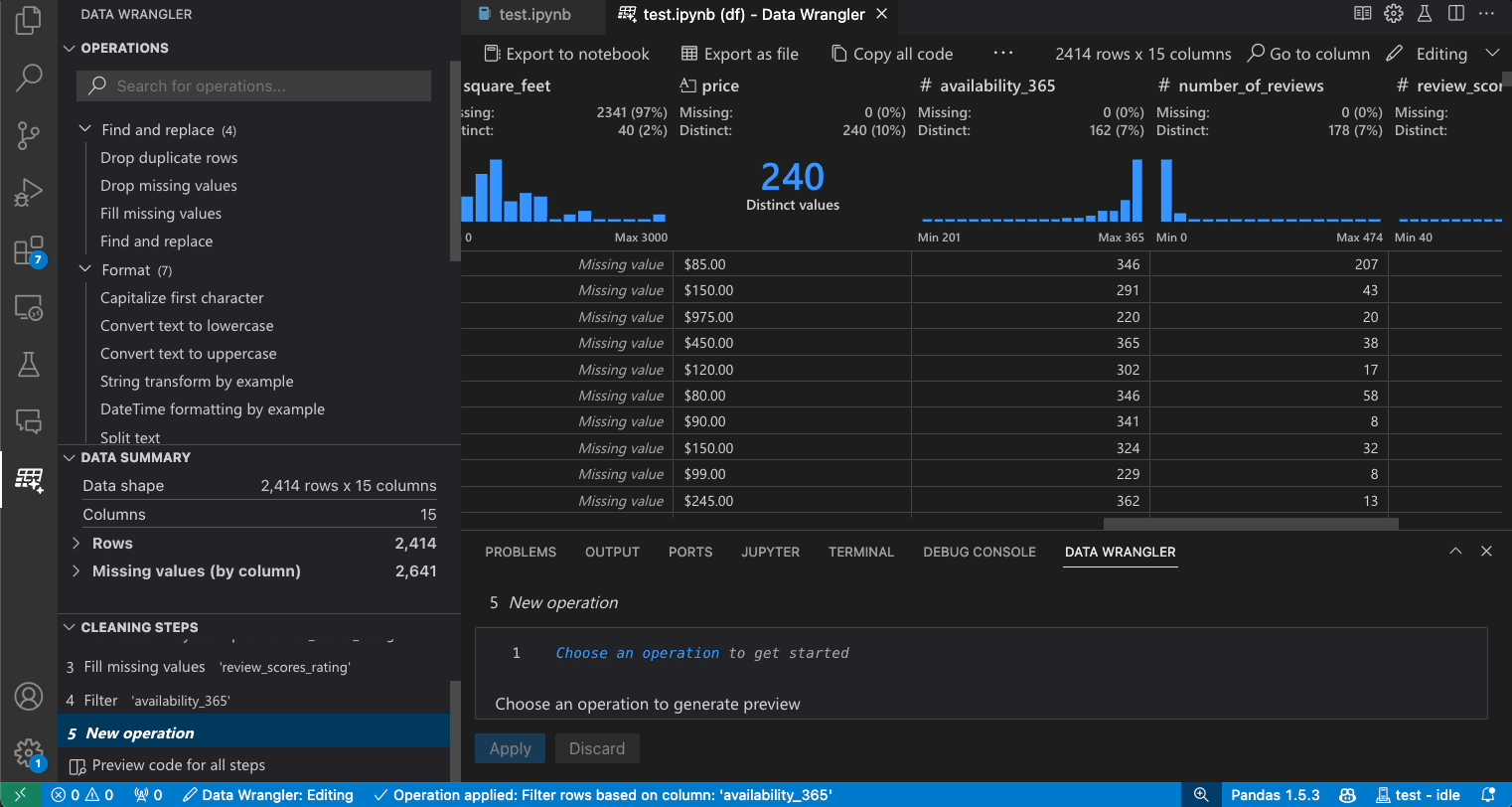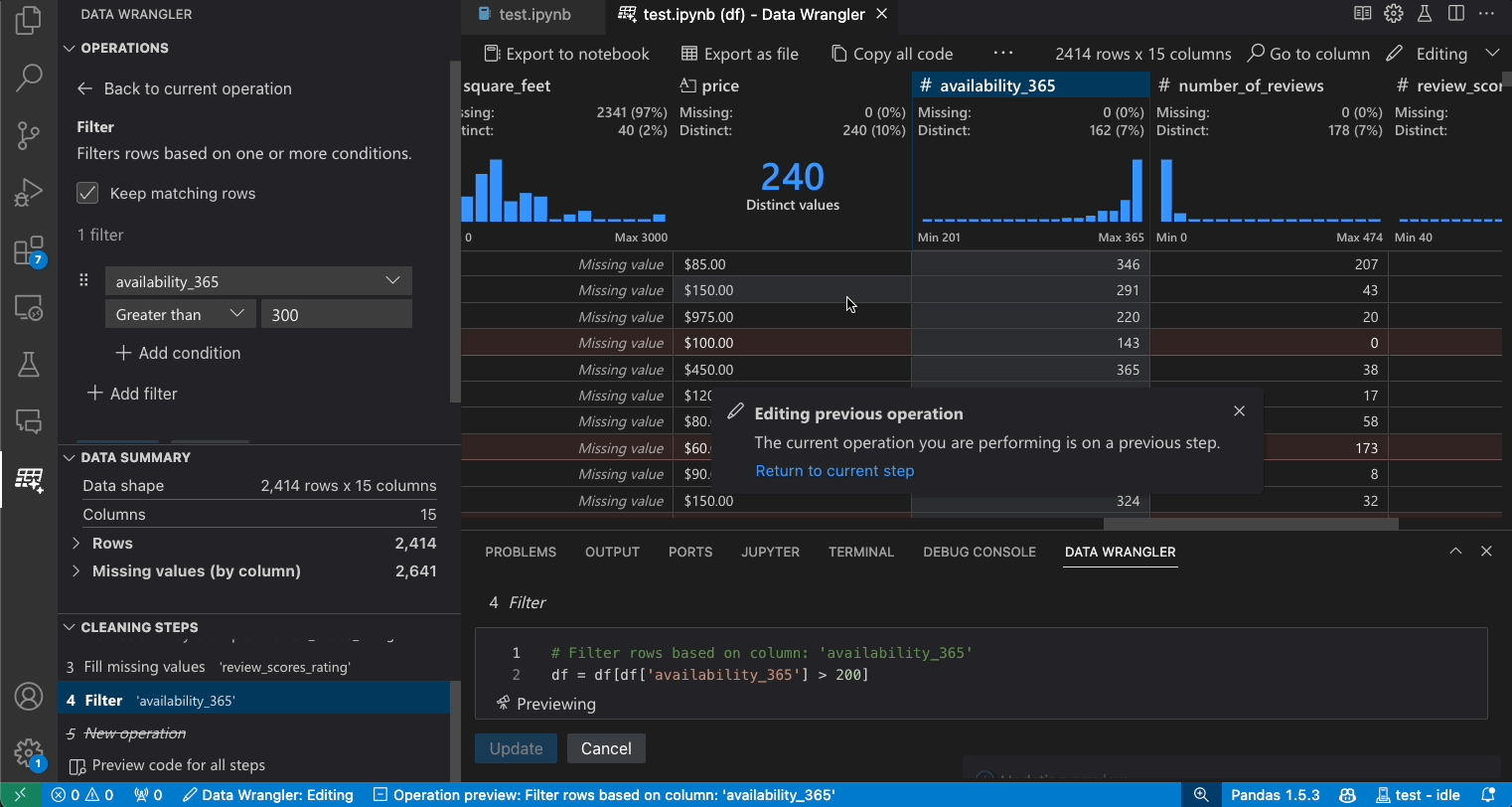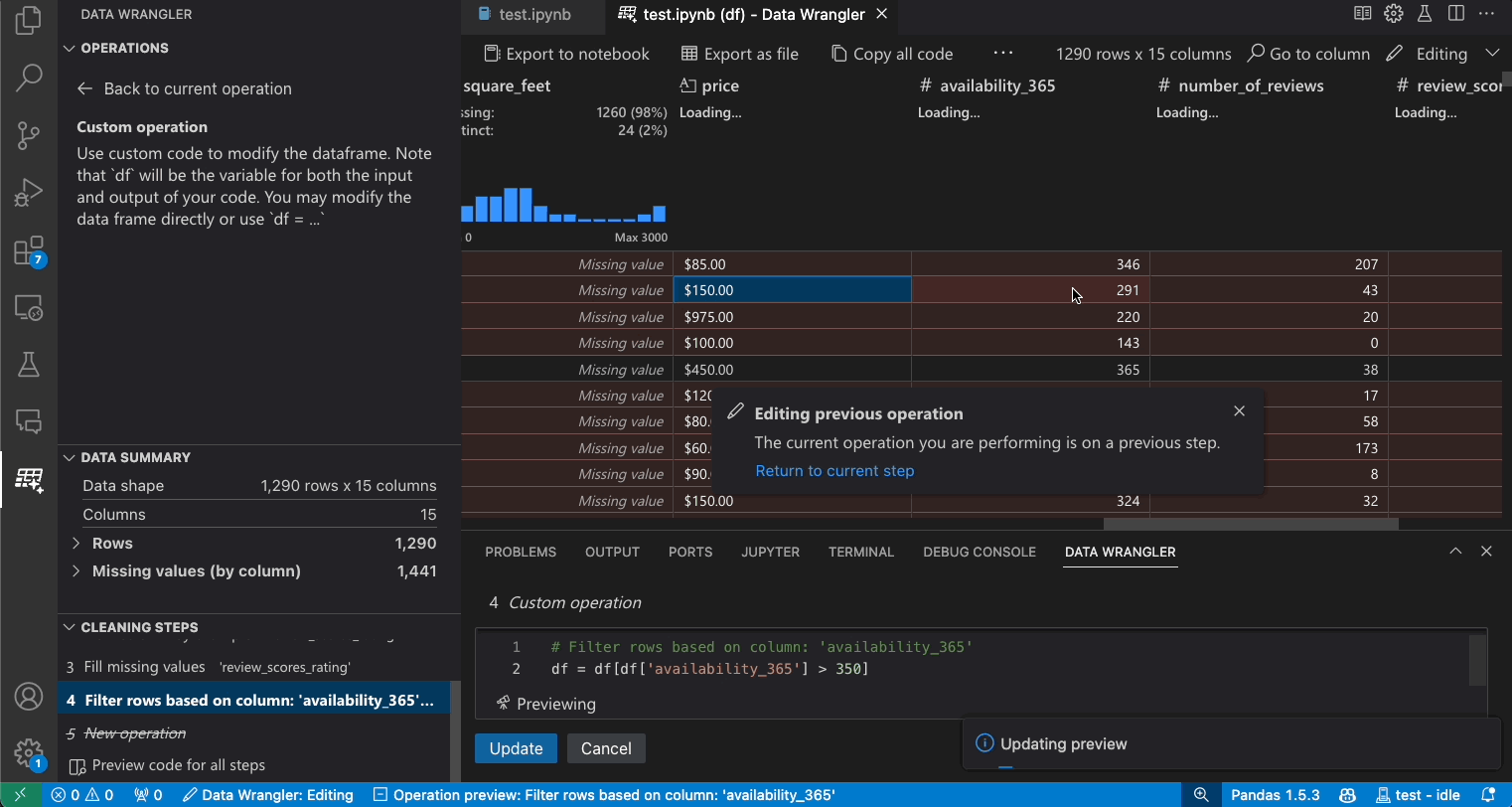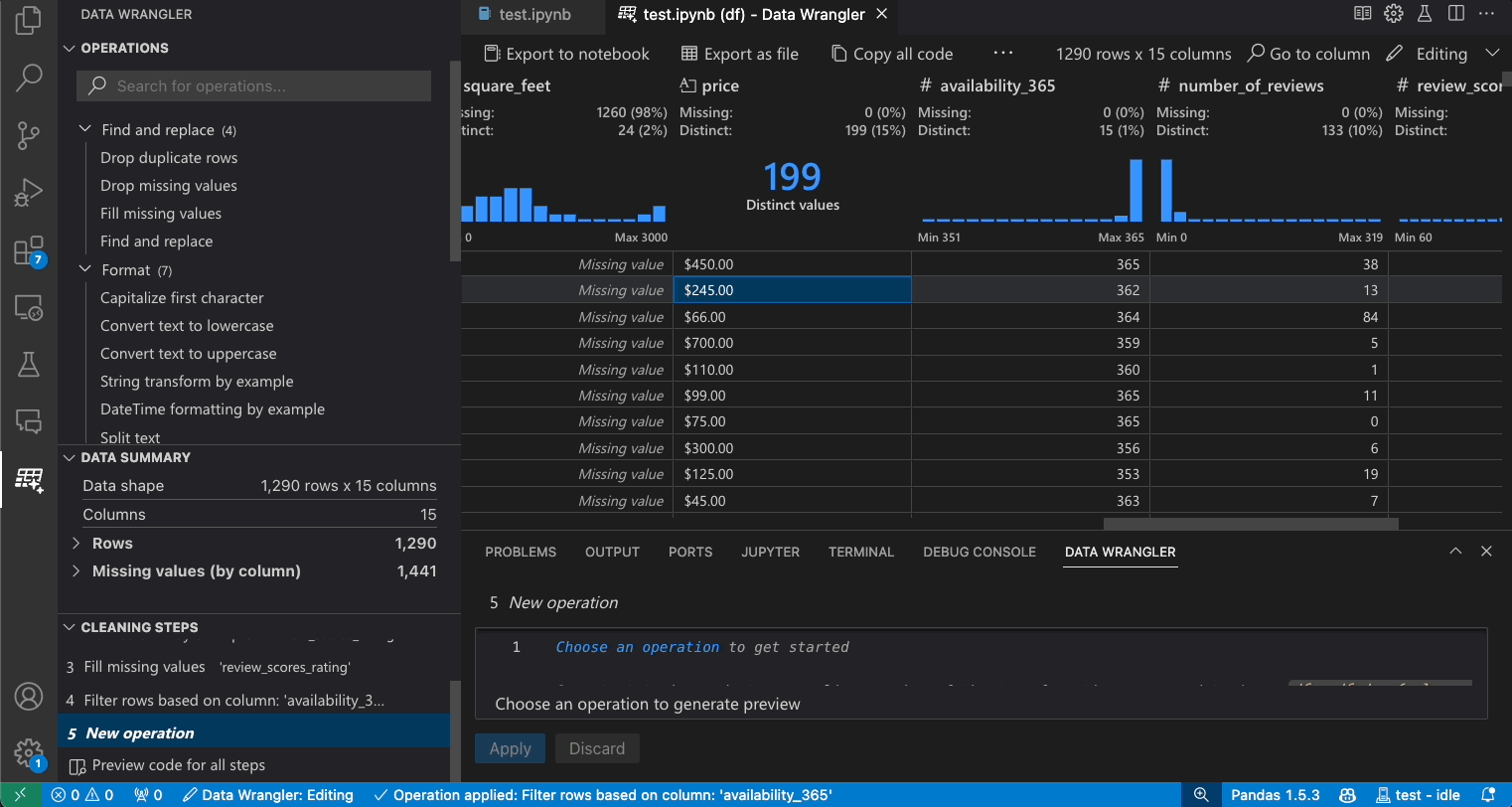
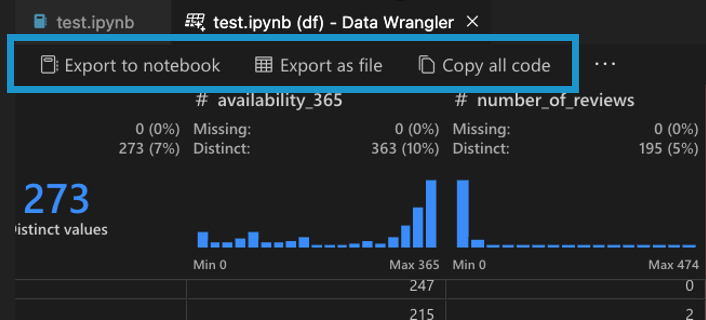
编辑和导出代码
一旦你在Data Wrangler中完成了数据清理步骤,有三种方法可以从Data Wrangler导出你清理过的数据集。
- 将代码导出回Notebook并退出: 这将在您的Jupyter Notebook中创建一个新单元格,其中包含您生成的所有数据清理代码,打包成一个Python函数。
- 将数据导出到文件: 这将清理后的数据集保存为新的CSV或Parquet文件到您的机器上。
- 复制代码到剪贴板: 这将复制由Data Wrangler生成的所有用于数据清理操作的代码。
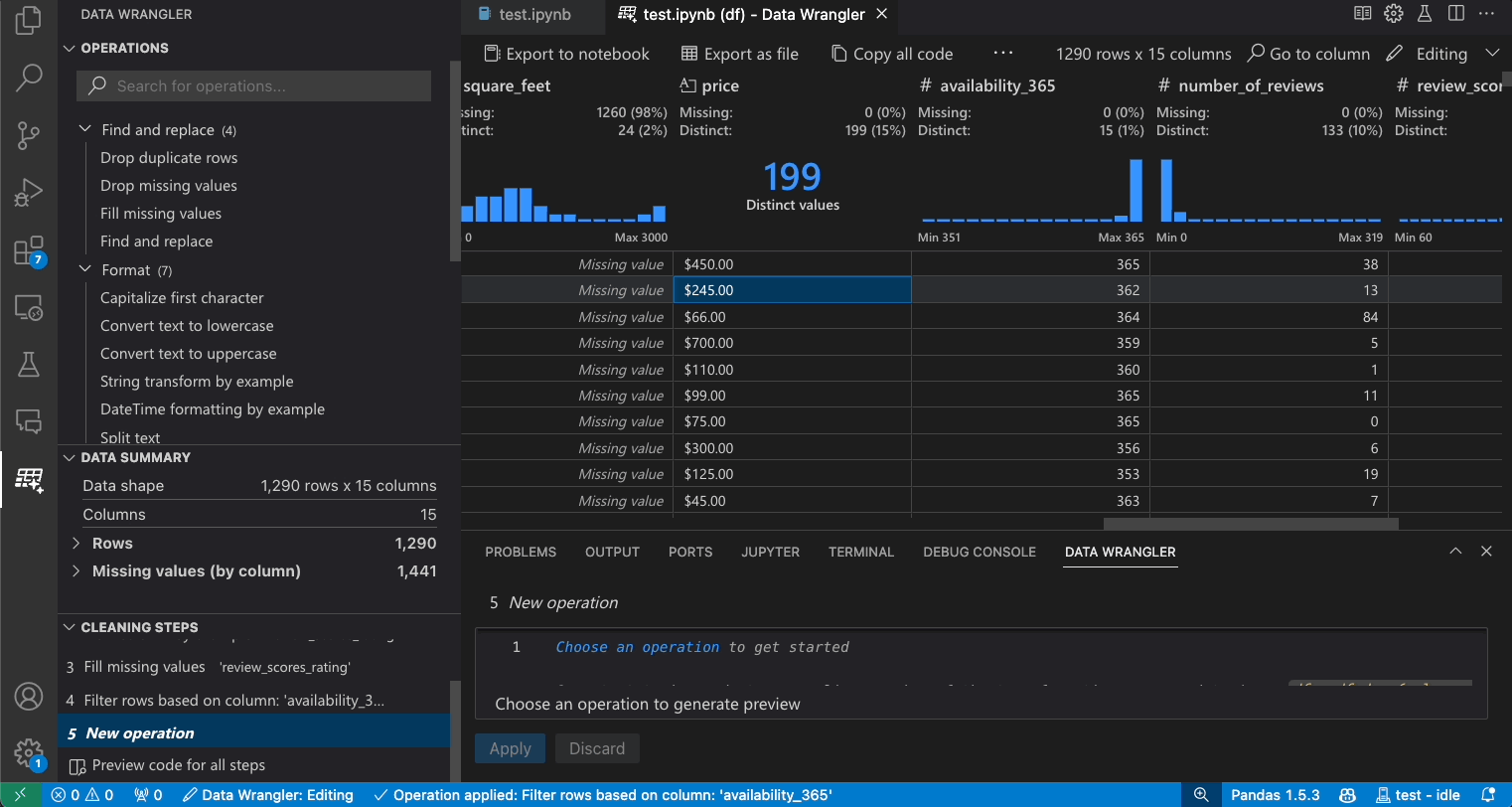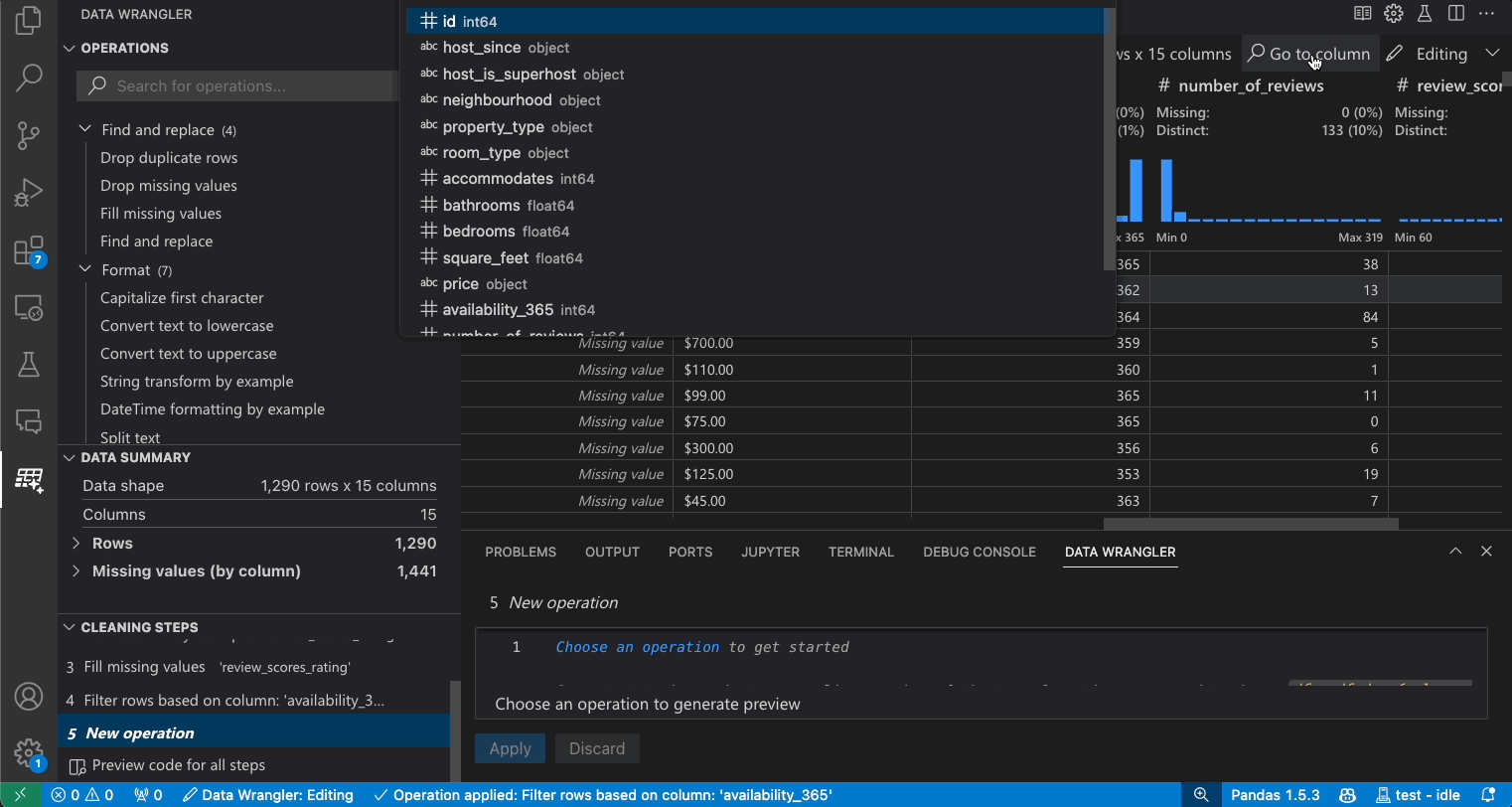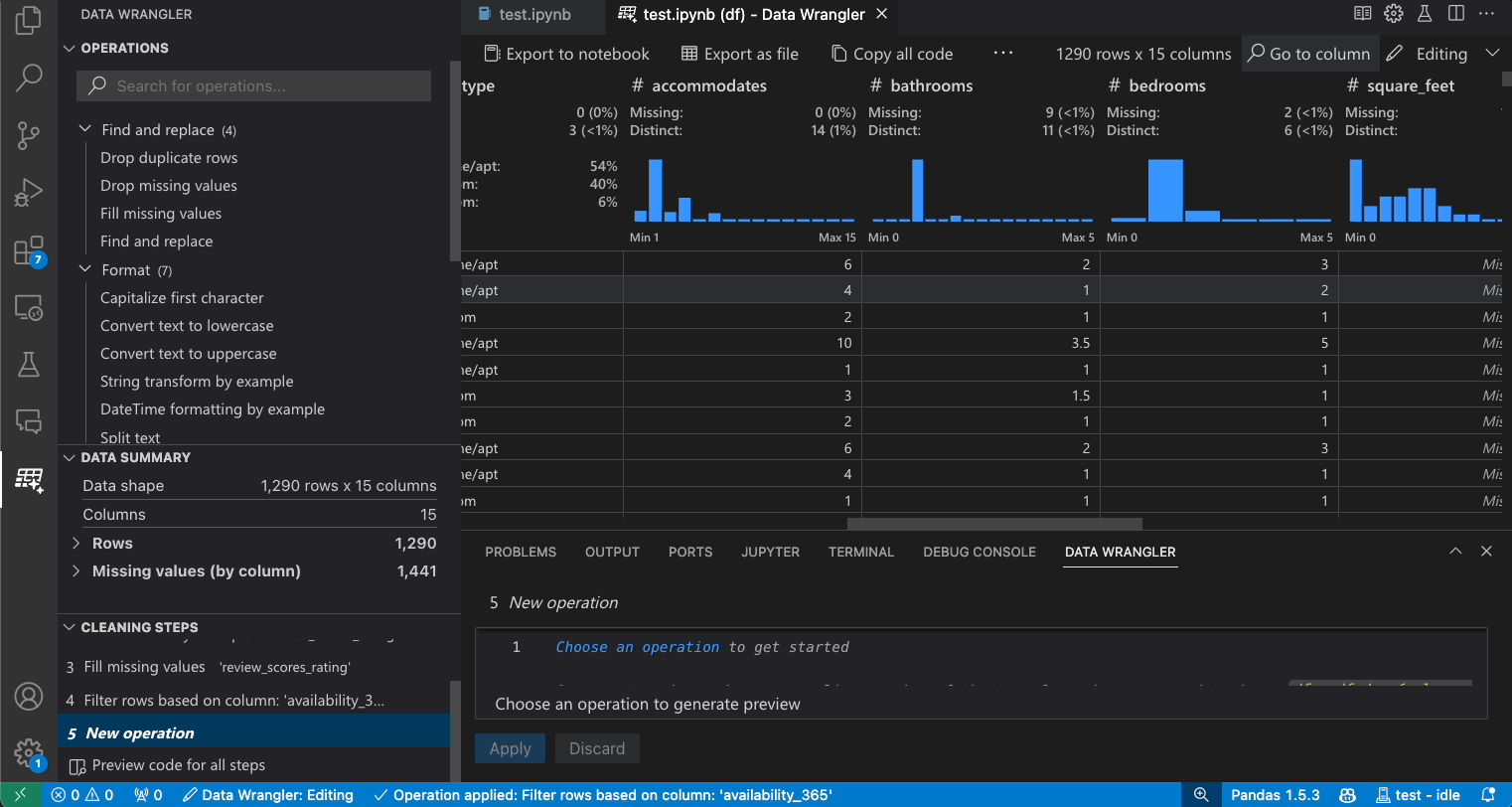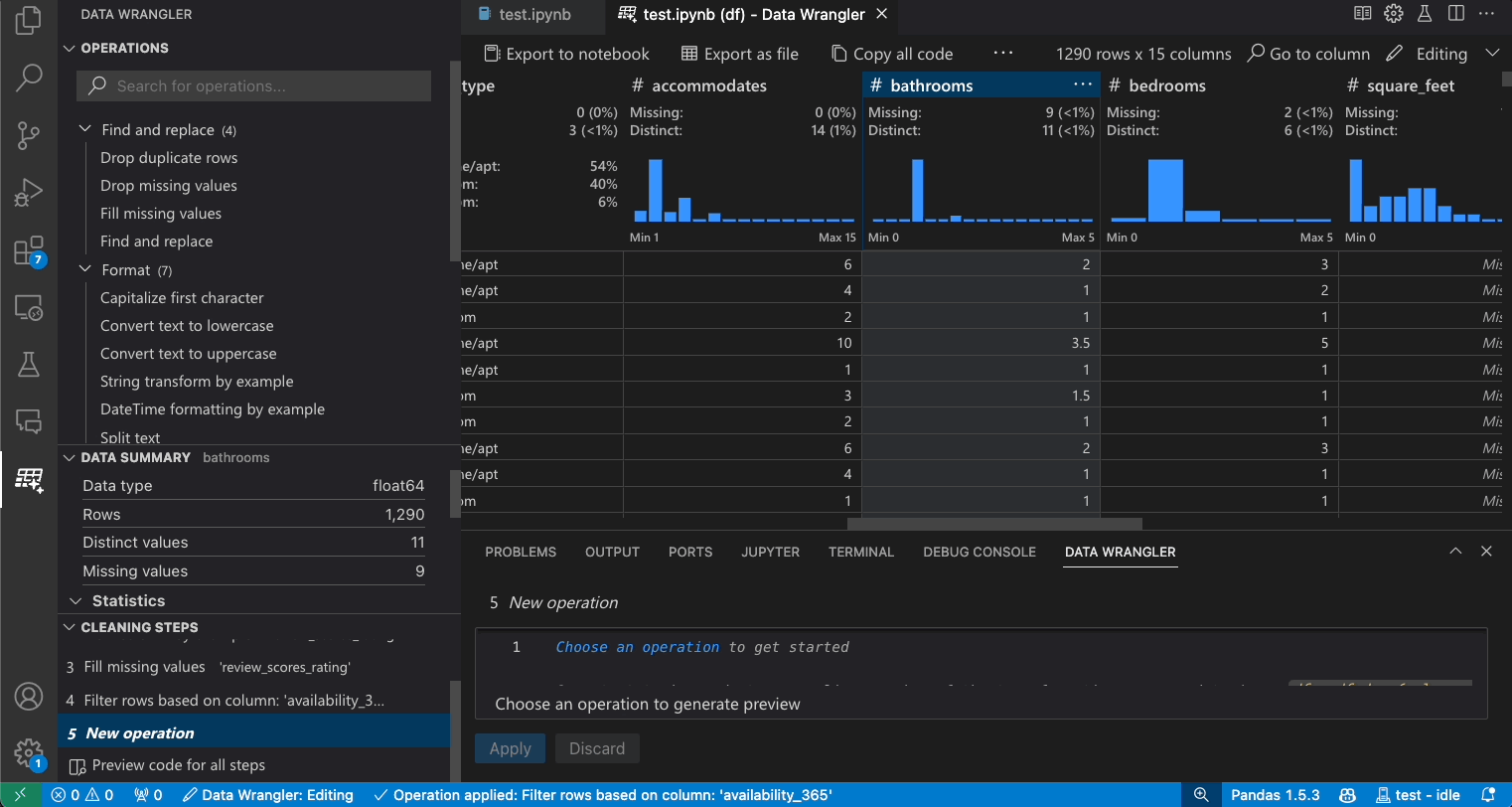
搜索列
要在数据集中查找特定列,请从数据整理工具栏中选择转到列并搜索相应的列。
故障排除
一般内核连接问题
对于一般的连接问题,请参阅上面的“连接到Python内核”部分,了解其他连接方法。要调试与本地Python解释器选项相关的问题,一种可能的解决方法是安装不同版本的Jupyter和Python扩展。例如,如果安装了扩展的稳定版本,您可以尝试安装预发布版本(反之亦然)。
要清除已缓存的内核,您可以从命令面板运行Data Wrangler: Clear cached runtime命令 ⇧⌘P (Windows, Linux Ctrl+Shift+P)。
打开数据文件时出现UnicodeDecodeError
如果你在直接从Data Wrangler打开数据文件时遇到UnicodeDecodeError,那么这可能是由两个可能的问题引起的:
- 您尝试打开的文件具有
UTF-8以外的编码 - 文件已损坏。
要解决此错误,您需要从Jupyter Notebook中打开Data Wrangler,而不是直接从数据文件中打开。使用Jupyter Notebook通过Pandas读取文件,例如使用read_csv方法。在read方法中,使用encoding和/或encoding_errors参数来定义要使用的编码或如何处理编码错误。如果您不知道哪种编码可能适用于此文件,可以尝试使用诸如chardet之类的库来推断适用的编码。
问题和反馈
如果您遇到问题、有功能请求或任何其他反馈,请在我们的GitHub仓库提交一个问题:https://github.com/microsoft/vscode-data-wrangler/issues/new/choose
数据和遥测
Visual Studio Code 的 Microsoft Data Wrangler 扩展会收集使用数据并将其发送给 Microsoft,以帮助我们改进产品和服务。阅读我们的隐私声明以了解更多信息。此扩展尊重 telemetry.telemetryLevel 设置,您可以在 https://code.visualstudio.com/docs/getstarted/telemetry 了解更多信息。