Note
Go to the end to download the full example code. or to run this example in your browser via Binder
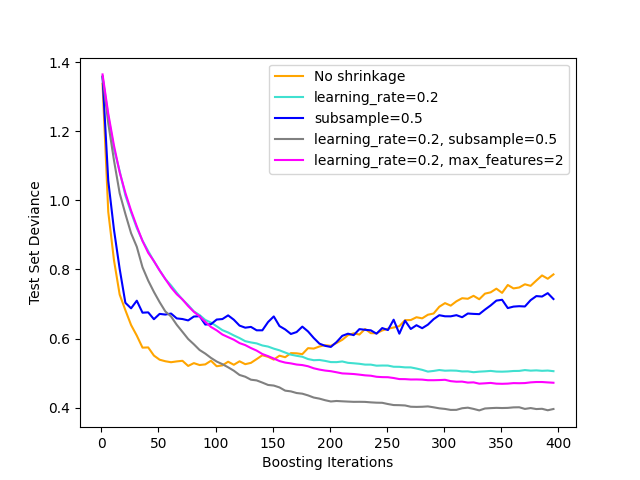
展示了不同正则化策略对梯度提升的影响。该示例取自 Hastie 等人 2009 [1]。
使用的损失函数是二项偏差。通过缩减( learning_rate < 1.0 )进行正则化可以显著提高性能。结合缩减,随机梯度提升( subsample < 1.0 )可以通过袋装法减少方差,从而产生更准确的模型。没有缩减的子采样通常表现不佳。另一种减少方差的策略是通过子采样特征,类似于随机森林中的随机分裂(通过 max_features 参数)。
# 作者:scikit-learn 开发者
# SPDX-License-Identifier: BSD-3-Clause
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, ensemble
from sklearn.metrics import log_loss
from sklearn.model_selection import train_test_split
X, y = datasets.make_hastie_10_2(n_samples=4000, random_state=1)
# 将标签从 {-1, 1} 映射到 {0, 1}
labels, y = np.unique(y, return_inverse=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8, random_state=0)
original_params = {
"n_estimators": 400,
"max_leaf_nodes": 4,
"max_depth": None,
"random_state": 2,
"min_samples_split": 5,
}
plt.figure()
for label, color, setting in [
("No shrinkage", "orange", {"learning_rate": 1.0, "subsample": 1.0}),
("learning_rate=0.2", "turquoise", {"learning_rate": 0.2, "subsample": 1.0}),
("subsample=0.5", "blue", {"learning_rate": 1.0, "subsample": 0.5}),
(
"learning_rate=0.2, subsample=0.5",
"gray",
{"learning_rate": 0.2, "subsample": 0.5},
),
(
"learning_rate=0.2, max_features=2",
"magenta",
{"learning_rate": 0.2, "max_features": 2},
),
]:
params = dict(original_params)
params.update(setting)
clf = ensemble.GradientBoostingClassifier(**params)
clf.fit(X_train, y_train)
# 计算测试集偏差
test_deviance = np.zeros((params["n_estimators"],), dtype=np.float64)
for i, y_proba in enumerate(clf.staged_predict_proba(X_test)):
test_deviance[i] = 2 * log_loss(y_test, y_proba[:, 1])
plt.plot(
(np.arange(test_deviance.shape[0]) + 1)[::5],
test_deviance[::5],
"-",
color=color,
label=label,
)
plt.legend(loc="upper right")
plt.xlabel("Boosting Iterations")
plt.ylabel("Test Set Deviance")
plt.show()
Total running time of the script: (0 minutes 9.342 seconds)
Related examples